# incremental_learning
**Repository Path**: tjljn/incremental_learning
## Basic Information
- **Project Name**: incremental_learning
- **Description**: No description available
- **Primary Language**: Python
- **License**: MIT
- **Default Branch**: master
- **Homepage**: None
- **GVP Project**: No
## Statistics
- **Stars**: 1
- **Forks**: 0
- **Created**: 2022-01-05
- **Last Updated**: 2022-07-20
## Categories & Tags
**Categories**: Uncategorized
**Tags**: None
## README
# Only Train Once: A One-Shot Neural Network Training And Pruning Framework
This repository is the Pytorch implementation of [Only Train Once (OTO): A One-Shot Neural Network Training And Pruning Framework](https://papers.nips.cc/paper/2021/hash/a376033f78e144f494bfc743c0be3330-Abstract.html), appearing in NeurIPS 2021.
 ## Reference
If you find the repo useful, please kindly cite our paper:
```
@inproceedings{chen2021only,
title={Only Train Once: A One-Shot Neural Network Training And Pruning Framework},
author={Chen, Tianyi and Ji, Bo and Tianyu, DING and Fang, Biyi and Wang, Guanyi and Zhu, Zhihui and Liang, Luming and Shi, Yixin and Yi, Sheng and Tu, Xiao},
booktitle={Thirty-Fifth Conference on Neural Information Processing Systems},
year={2021}
}
```
## Zero-Invariant Group (ZIG)
Zero-invariant groups serve as one of two fundamental components to OTO. A ZIG has an attractive property is that if equaling to zero, then the corresponding structure contributes null to the model output, thereby can be directly removed. ZIG is generic to various DNN architectures, such as Conv-Layer, Residual Block, Fully-Connected Layer and Multi-Head Attention Layer as follows.
## Reference
If you find the repo useful, please kindly cite our paper:
```
@inproceedings{chen2021only,
title={Only Train Once: A One-Shot Neural Network Training And Pruning Framework},
author={Chen, Tianyi and Ji, Bo and Tianyu, DING and Fang, Biyi and Wang, Guanyi and Zhu, Zhihui and Liang, Luming and Shi, Yixin and Yi, Sheng and Tu, Xiao},
booktitle={Thirty-Fifth Conference on Neural Information Processing Systems},
year={2021}
}
```
## Zero-Invariant Group (ZIG)
Zero-invariant groups serve as one of two fundamental components to OTO. A ZIG has an attractive property is that if equaling to zero, then the corresponding structure contributes null to the model output, thereby can be directly removed. ZIG is generic to various DNN architectures, such as Conv-Layer, Residual Block, Fully-Connected Layer and Multi-Head Attention Layer as follows.
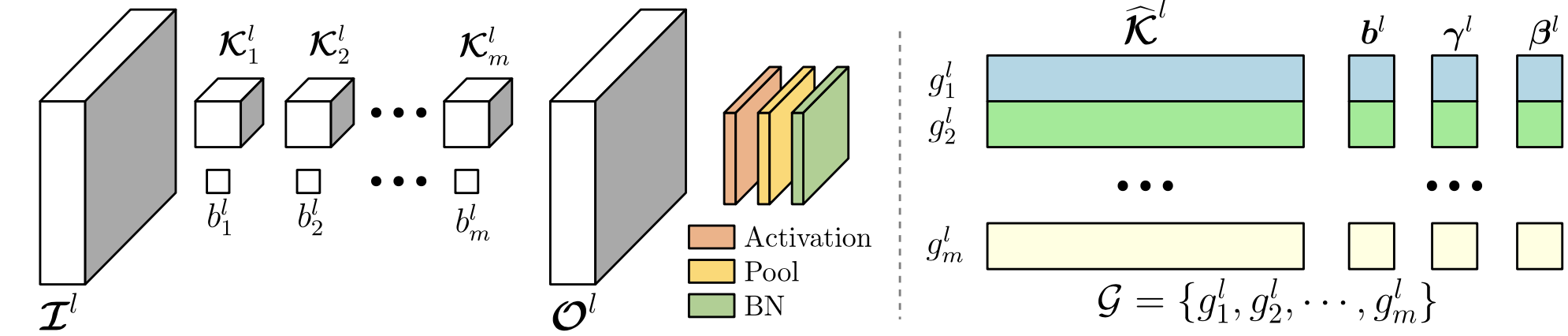
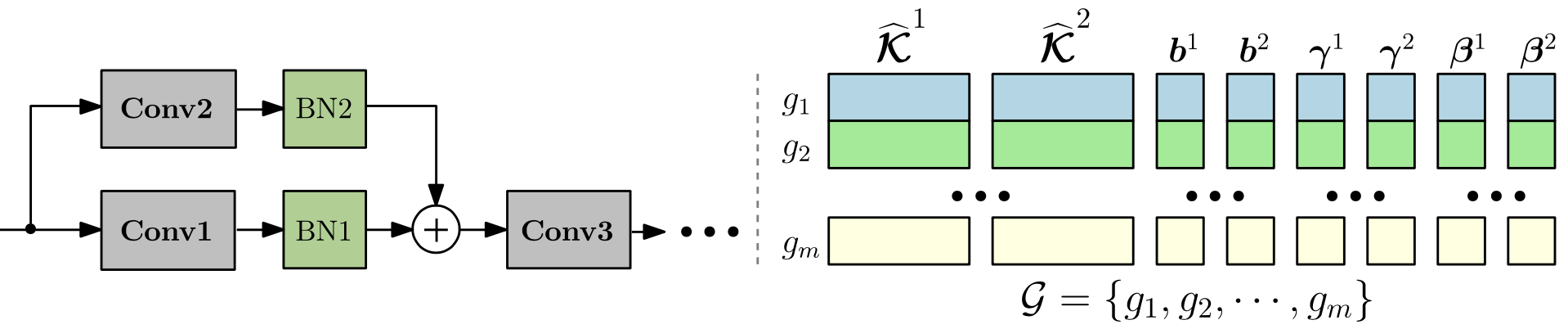
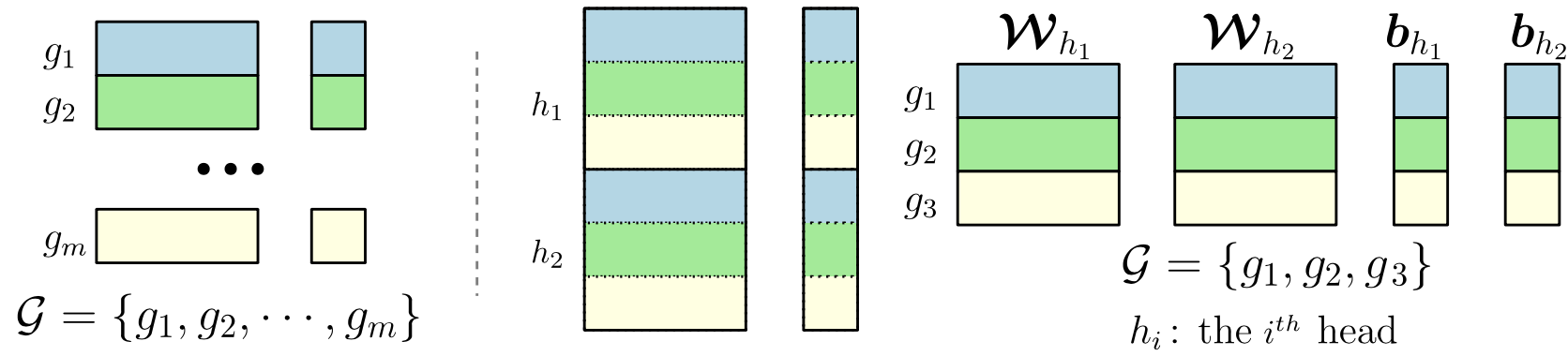 ## Half-Space Projected Gradient Descent Method (HSPG)
Half-Space Projected Gradient Descent Method serve as another fundamental component to OTO to promote more ZIGs as zero. Hence, redundant structures can be pruned without retraining. HSPG utilizes a novel Half-Space projection operator to yield group sparsity, which is more effective than the standard proximal method because of a larger projection region.
## Half-Space Projected Gradient Descent Method (HSPG)
Half-Space Projected Gradient Descent Method serve as another fundamental component to OTO to promote more ZIGs as zero. Hence, redundant structures can be pruned without retraining. HSPG utilizes a novel Half-Space projection operator to yield group sparsity, which is more effective than the standard proximal method because of a larger projection region.
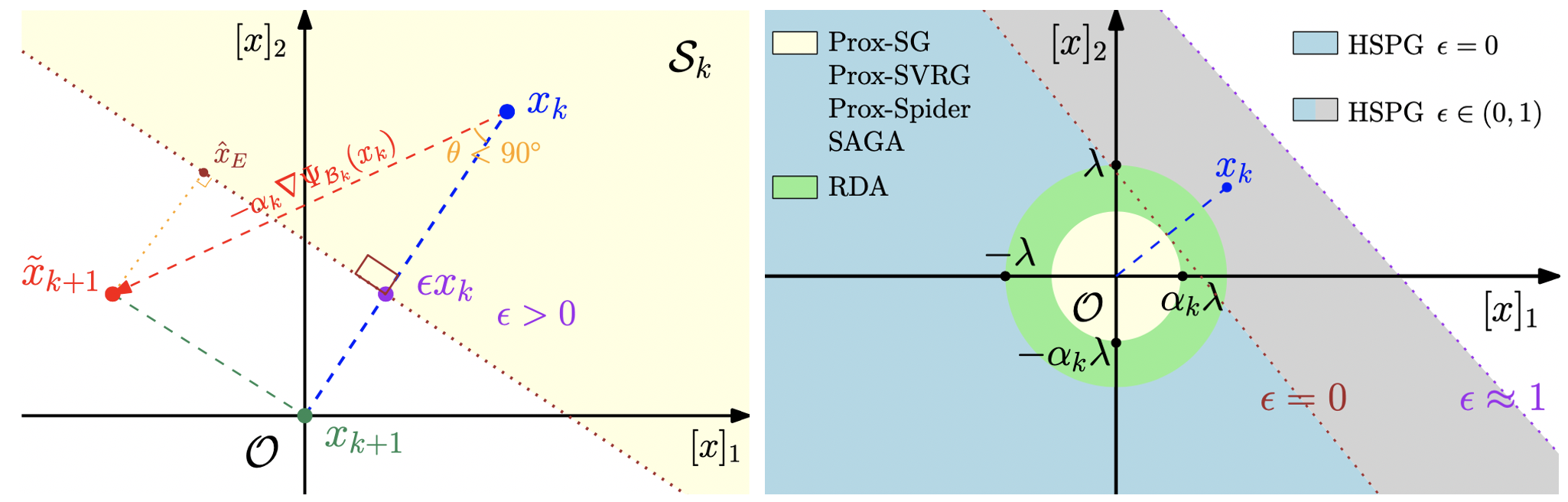 ## Pretrained full group sparse models and slimmer pruned models
To reproduce the results shown in the main body of paper, we provide our pretrained full group sparse models by HSPG.
These full group sparse models can be directly pruned by the following scripts to generate slimmer models with the exact same performance as the full group sparse models.
They can be downloaded via this [link](https://drive.google.com/drive/folders/1MCpbU-RYNr8gUoD3xFQSCuXaUP_Aj0Fa?usp=sharing).
## Pruning
To prune the full group sparse CNN models and construct the slimmer pruned models, run the this command:
+ backend: [vgg16|vgg16\_bn|resnet50]
+ dataset\_name: [cifar10|imagenet]
```prune
python prune/prune_cnn.py --backend --dataset_name --checkpoint
```
For examples,
```
python prune/prune_cnn.py --backend vgg16 --dataset_name cifar10 --checkpoint checkpoints/vgg16_cifar10_group_sparse.pt
```
To prune the full group sparse Bert models and construct the slimmer pruned Berts, run the this command:
```
python prune/prune_bert_squad.py --checkpoint_dir --eval_data
```
For example,
```
python prune/prune_bert_squad.py --checkpoint_dir checkpoints/bert_squad_oto_params_40_exact_71_f1_81 --eval_data data/squad/dev-v1.1.json
```
The above pruning script generates corresponding pruned models in checkpoints dir, which return the exact same output as the full group sparse models.
## Training
To train the CNNs, run the below commands:
```
python prune/run_cnn.py --opt
```
For example,
```train
python train/run_cnn.py --opt train/configs/config_vgg16_bn_hspg.yml
python train/run_cnn.py --opt train/configs/config_resnet50_cifar10_hspg.yml
```
To train the Berts in the paper, run this command:
```
python prune/run_bert_squad.py --opt
```
For example,
```train
python train/run_bert_squad.py --opt train/configs/config_bert_squad_hspg_upgs_0.5.yml
```
## Results
Our pruned models achieve the following performance on :
### [Pruned VGG16 on CIFAR10]
| FLOPs | # of Params | Top 1 Accuracy |
| -------- | ----------- | ---------------- |
| 16.3% | 2.5% | 91.0% |
### [Pruned VGG16-BN on CIFAR10]
| FLOPs | # of Params | Top 1 Accuracy |
| -------- | ----------- | ---------------- |
| 26.8% | 5.5% | 93.3% |
### [Pruned ResNet50 on CIFAR10]
| FLOPs | # of Params | Top 1 Accuracy |
| -------- | ----------- | ---------------- |
| 12.8% | 8.8% | 94.4% |
### [Pruned ResNet50 on ImageNet]
| FLOPs | # of Params | Top 1 Accuracy | Top 5 Accuracy |
| -------- | ----------- | ---------------- | -------------- |
| 34.5% | 35.5% | 74.7% | 92.1% |
### [Pruned Berts on SQuAD]
| # of Params | Exact | F1-Score |
| ----------- | ----------- | ----------- |
| 91.0% | 75.0% | 84.1% |
| 76.2% | 72.3% | 82.1% |
| 66.7% | 71.9% | 82.0% |
| 53.3% | 71.4% | 81.5% |
| 40.0% | 70.9% | 81.1% |
## Contributing
The source code for the site is licensed under the MIT license.
## Pretrained full group sparse models and slimmer pruned models
To reproduce the results shown in the main body of paper, we provide our pretrained full group sparse models by HSPG.
These full group sparse models can be directly pruned by the following scripts to generate slimmer models with the exact same performance as the full group sparse models.
They can be downloaded via this [link](https://drive.google.com/drive/folders/1MCpbU-RYNr8gUoD3xFQSCuXaUP_Aj0Fa?usp=sharing).
## Pruning
To prune the full group sparse CNN models and construct the slimmer pruned models, run the this command:
+ backend: [vgg16|vgg16\_bn|resnet50]
+ dataset\_name: [cifar10|imagenet]
```prune
python prune/prune_cnn.py --backend --dataset_name --checkpoint
```
For examples,
```
python prune/prune_cnn.py --backend vgg16 --dataset_name cifar10 --checkpoint checkpoints/vgg16_cifar10_group_sparse.pt
```
To prune the full group sparse Bert models and construct the slimmer pruned Berts, run the this command:
```
python prune/prune_bert_squad.py --checkpoint_dir --eval_data
```
For example,
```
python prune/prune_bert_squad.py --checkpoint_dir checkpoints/bert_squad_oto_params_40_exact_71_f1_81 --eval_data data/squad/dev-v1.1.json
```
The above pruning script generates corresponding pruned models in checkpoints dir, which return the exact same output as the full group sparse models.
## Training
To train the CNNs, run the below commands:
```
python prune/run_cnn.py --opt
```
For example,
```train
python train/run_cnn.py --opt train/configs/config_vgg16_bn_hspg.yml
python train/run_cnn.py --opt train/configs/config_resnet50_cifar10_hspg.yml
```
To train the Berts in the paper, run this command:
```
python prune/run_bert_squad.py --opt
```
For example,
```train
python train/run_bert_squad.py --opt train/configs/config_bert_squad_hspg_upgs_0.5.yml
```
## Results
Our pruned models achieve the following performance on :
### [Pruned VGG16 on CIFAR10]
| FLOPs | # of Params | Top 1 Accuracy |
| -------- | ----------- | ---------------- |
| 16.3% | 2.5% | 91.0% |
### [Pruned VGG16-BN on CIFAR10]
| FLOPs | # of Params | Top 1 Accuracy |
| -------- | ----------- | ---------------- |
| 26.8% | 5.5% | 93.3% |
### [Pruned ResNet50 on CIFAR10]
| FLOPs | # of Params | Top 1 Accuracy |
| -------- | ----------- | ---------------- |
| 12.8% | 8.8% | 94.4% |
### [Pruned ResNet50 on ImageNet]
| FLOPs | # of Params | Top 1 Accuracy | Top 5 Accuracy |
| -------- | ----------- | ---------------- | -------------- |
| 34.5% | 35.5% | 74.7% | 92.1% |
### [Pruned Berts on SQuAD]
| # of Params | Exact | F1-Score |
| ----------- | ----------- | ----------- |
| 91.0% | 75.0% | 84.1% |
| 76.2% | 72.3% | 82.1% |
| 66.7% | 71.9% | 82.0% |
| 53.3% | 71.4% | 81.5% |
| 40.0% | 70.9% | 81.1% |
## Contributing
The source code for the site is licensed under the MIT license.