| Query String | Tuples | Comment |
|---|---|---|
| A | (1) | The root of the tree |
| ?A | (1),(2),(3),(4),(5),(6) | An arbitrary node in a tree |
| ?A(B) | (5,6) | An arbitrary node, that has only one child, and this child |
| ?A(B,C) | (1,2,5), (2,3,4) | An arbitrary node in a tree with its two children in fixed order |
| ?A(.B,.C) | (1,2,5), (1,5,2), (2,3,4), (2,4,3) | An arbitrary node with its two children in unconditioned order |
| ?A(.B) | (1,2), (2,3), (2,4), (5,6) | An arbitrary node with its one child |
| ?A(?B) | (1,2), (1,3), (1,4), (1,5), (1,6), (2,3), (2,4), (5,6) | An arbitrary node with its arbitrary descendant |
| ?A(?B(?C)) | (1,2,3), (1,2,4), (1,5,6) | An arbitrary node, its descendant and descendant of the descendant |
| ?A(?B(C,D)) | (1,2,3,4) | An arbitrary node that has a descendant with two child |
Rule.SelectWhere, which takes array of INode, generates IEnumerable<SelectOutput> and passes this enumeration to delegate where
with type Func<SelectOutput,WhereOutput>. This delegate verify the matching of the tuple to the filter and generates WhereOutput object, corresponding to the filtered tuple.
## Modification ##
When selection stage is over, we obtain several tuples that could be modified in the modification stage. However, only one of them will be actually processed, because application of the rule may invalidate other tuples.
Therefore, modification stage processes only one of the selected tuples. We have developed a "clean" modification, which does not affect the initial trees. Instead, in the modification stage we create a copy of selected
trees, and perform modification on the copy. To do that, we must find the roots of nodes, presented in a given tuple, clone them, and further process a newly created tuple with a corresponding clones of nodes.
For this functionality responds method Rule.Apply, which takes WhereOutput object. Than it makes copy of this object through method WhereOutput.MakeSafe and passes this copy to
delegate apply, where modification performs.
## Creating new rule ##
Full rule definition looks like this:
```csharp
Rule
.New("+0", StdTags.Algebraic, StdTags.Simplification, StdTags.SafeResection)
.Select(AnyA[ChildB, ChildC])
.Where<Arithmetic.Plus<double>, Constant<double>, INode>(z => z.B.Value == 0)
.Mod(z => z.A.Replace(z.C.Node));
```
This rule looks for subtrees *X+0* or *0+X* and replaces them with *X*. We have already defined a few collections of rules to implement some functionality and further we will tell you what exactly
you can do with the system to date.
# Simplification and Differentiation #
You can find rules for simplification and differentiation in classes AlgebraicRules and DifferentiationRules accordingly. To simplify expression with existing rules use method
ComputerAlgebra.Simplify like this:
```csharp
ExpressionComputerAlgebra.Differentiate:
```csharp
ExpressionSimplificationDemo, DifferentiateDemo, and in test classes SimpleTests, DifferentiationTest
# Regression #
The first aim of our research was symbolic regression task, where we used simplification rules to improve the existed solutions of evolutionary symbolic computations. In symbolic regression, genetic algorithm processes
expressions with mutation and crossover, and gradually creates the expression that fits experimental data. Constants in expressions are found also by mutation. We improve this part of algorithm with standard well-known
numerical regression. Suppose the algorithm has found function *F(x1,...,xn)* as the potential solution. Let *Φ(x1,...,xn,c1,...,cm)* be a
function *F* where constants are replaced with arguments *ci*. Let *E(c1,...,cm)* be an error function:
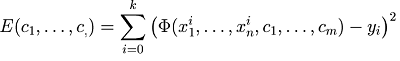
where the set  is the experimental data. With differentiation rules, we can calculate
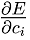 and improve *ci*
with gradient descent so *Φ* fits experimental data better. This technique is experimentally tested and proved to be better than finding constants with genetic algorithm.
We have decided to split evolutionary algorithms and symbolic computation, so now you can use numerical regression regardless of the genetic algorithm. To do that you should create new instance of
RegressionAlgorithm class and call method Run(). The constructor of RegressionAlgorithm takes expression, experimental data, accurance and initial step for gradient descent.
You can find the examples of this in RegressionDemo project and RegressionTests class.
# Resolution #
The resolution technique is very simple:
1. Find two clauses containing the same predicate, where it is negated in one clause but not in the other.
2. Perform a unification on the two predicates. (If the unification fails, you made a bad choice of predicates. Go back to the previous step and try again.)
3. If any unbound variables which were bound in the unified predicates also occur in other predicates in the two clauses, replace them with their bound values (terms) there as well.
4. Discard the unified predicates, and combine the remaining ones from the two clauses into a new clause, also joined by the ∨ operator.
All predicates must be in Skolem normal form, therefore we needs some tool to define quantifier-free part of such predicates. To do that we have generated several methods and constants. So now, we can define
formulas in the following form:
```csharp
ExpressionUnificationService class. It's very simple, so we will not describe it here.
The main part of this technique, the resolution rule, is implemented as standard rule of this system:
```csharp
Rule
.New("Resolve", StdTags.Inductive, StdTags.Logic, StdTags.SafeResection)
.Select(A[ChildB], C[ChildD])
.WhereModificator method perfoms a unification on the two predicates and combine the remaining ones from the two clauses into a new clause.
To get list of possible resolvents of two predicates you must use the method ComputerAlgebra.Resolve like this:
```csharp
ExpressionResolutionDemo and in test class ResolutionTests