# GIT-CCode-Study
**Repository Path**: huangshaomo/git-ccode-study
## Basic Information
- **Project Name**: GIT-CCode-Study
- **Description**: C语言学习笔记
- **Primary Language**: Unknown
- **License**: Not specified
- **Default Branch**: master
- **Homepage**: None
- **GVP Project**: No
## Statistics
- **Stars**: 0
- **Forks**: 0
- **Created**: 2021-06-16
- **Last Updated**: 2021-06-23
## Categories & Tags
**Categories**: Uncategorized
**Tags**: None
## README
# GIT-CCode-Study
#### 介绍
C语言学习笔记
**主板**:主板的英文是Mainboard,是电脑各个配件的连接平台,相当于人体的血管、神经和骨骼系统。主板上最关键的是芯片组,**芯片组**的型号决定了主板的型号,**芯片组决定了主板上各种插槽、总线、接口可以支持的速度和功能**,有的芯片组还集成了显示、声音、网络等功能。 电脑的内存需要插到主板的特定插槽中。其他电脑配件例如显卡、声卡等通过插槽垂直插在主板上,硬盘、光驱、软驱等内部存储设备通过数据线和主板上的各类接口连接。将电源通过连线插到主板上之后,由主板向电脑各个配件供电,主板上还有连接各种外部设备的接口。 所有的电脑硬件信息都保存在主板上的CMOS中,通过BIOS系统我们可以轻易的调整各种配置。主板的品牌包括华硕、微星、精英、联想、技嘉、升技、磐英、承启等。
**硬盘**:硬盘是用来存储数据的地方:分为固态硬盘和机械硬盘
1. 固态硬盘:通过**电路**来读写数据,但是因为与内存的控制方式不一样,速度也不及内存。
2. 机械硬盘:通过**电机**来读写数据,转速肯定没有电的传输速度(几乎是光速)快

**内存**:内存只是一个存放数据和指令的地方,并不能进行运算,如果要进行运算,必须要读取到CPU内部才能进行加法运算
对于读写速度,内存 > 固态硬盘 > 机械硬盘。
**CPU**:CPU 是一个复杂的计算机部件,它内部又包含很多多的小零件,如下图所示:
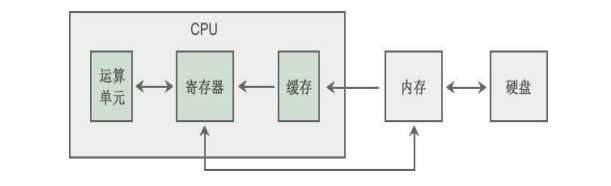
1. 运算单元:是 CPU 的大脑,负责加减乘除、比较、位运算等工作,每种运算都有对应的电路支持,速度径快。
2. 寄存器:
3. 缓存:虽然内容的读取速度已经很快了,但和CPU比起来,也不是一个数量级的,因此与其把计算的结果返回给内容,还不如再复制一份结果存到缓存中,这样,对于可以将使用频繁的数据暂时读取到缓冲,需要同一地址上的数据时,就不用大老远地再去访问内容,直接从缓存中读取不更快。
CPU的运算可以从内存和地址中拿到数值进行运算
CPU的(1小时)处理数据的大小由寄存器的个数和数据总线的宽度(也即有多少根数据总线)决定,我们通常说的多少位的CPU,除了可以理解为寄存器的位数,也可以理解为数据总线的宽度,通常情况下他们 是相等 的
**虚拟地址**:把程序给出的地址看做是一种**虚拟地址(virtual address)**,然后通过内存映射机制,将这个虚拟地址转换成真实的物理地址,之所以需要虚拟地址,是因为不同的程序可能会使用同一个地址,这样就会造成其中一个程序无法运行或者强行占用导致另一个程序崩溃,这对于需要安全稳定的计算机环境的用户来说是不能容忍的,因此,程序给出的地址系统会把它看成虚拟的地址,通过内存映射机制将虚拟地址与真实物理地址之间建立映射关系,这样,即使其他程序中也使用到了同一个地址,映射机制也会把它映射到其他的真实物理地址当中去,这样不同程序之间的地址空间就相互隔离开了,无论对一个程序如何进行操作,都不会修改到对方的内存,自然就不会导致其他程序奔溃了。
使用虚拟地址还有一个好处是能够提高内存的使用效率,因为一旦使用了虚拟地址,操作系统便有了管理内存的能力,就可以介入到内存管理工作中,不仅能灵活的控制数据换入换出的力度,更可以控制内存的读取权限。针对性使用习惯定制化的管理内存,自然就提高了内存的使用效率。
**中间层思想:**
所谓中间层,就是使用一种间接的方式来屏蔽复杂的底层细节,只给用户提供简单的调用接口。实际上,计算机的整个发展就是不断引入新的中间层的过程。
中间层:javaScript > C语言 > 汇编语言 > 机械指令,
最底层的是机械指令,经过层层套壳到JS,我们用到的经过几层封装后的指令,越顶层的制作的效率越快,越底层的执行效率越快。
**内存对齐**
计算机内存以字节(Byte)为单位划分的,理论上CPU可以访问内存中任意编号的字节,但实际情况并非如此。
CPU访问内存是通过地址总线来访问的。CPU一次性能处理几个字节的数据,就命令地址总线读取几个字节的数据,32为位的CPU一次可以处理4个字节的数据,那么每次就从内存读取四个字节的数据。少了浪费主频,多了没有用。64位的处理器也是这个道理,每次读取8个字节。而每次读取字节的个数,就称为步长,32位的步长为4。**将一个数据尽量放在一个步长之内,避免跨步长存储,这就称为内存对齐**,在32位编译模式下,默认以4字节对齐,在64位编译模式下,默认以8字节对齐
内存对齐并非C语言专有,它属于计算机的运行原理,C++,java,python等其他变成语言同样也会有内存对齐的问题。
#### 编程基础
##### 1.1 数据在内存中的存储
计算机要处理的信息是多种多样的,如数字,文字,符号,图形,音频等等,这些信息虽然在人们的眼里是不通的,但在计算机眼中,它们都是存储在内存中的二进制数据。
计算机处理数据的基础就是二进制
内存条是一个非常精密的部件,包含了上亿个电子元器件,它们很小,达到纳米级别,这些元器件实际上就是电路,电路的电压会变化,要么是0V,要么是5V,只有这两种电压,5V是通电,用1来表示,0V是断电,用0来表示,所以,一个元器件有两种状态,0或者1.
我们通过电路来控制这些元器件的通断电,会得到很多的0,1的组合,例如,8个元器件有$2^8$ = 256中不同的组合,16个元器件有$2^{16}$ =65536种不通的组合,虽然一个元器件只能表示2个数值,但是多个组合起来能表示的数值呈指数级增长。
$2^8$ - 1 = $2^0$ + $2^1$+$2^2$+$2^3$+$2^4$+$2^5$ +$2^6$+$2^7$ = 1 + 2 + 4 + 8 + 16 + 32 +64 + 128 = 255;
一般情况下我们是以8个元器件看作一个单位,一个元器件称为1比特,8个 元器件称为1字节(Byte),那么16个元器件就是2Byte,32个元器件就是4Byte,以此类推:
- 8 x 1024个元器件就是 1024Byte,简写1KB
- 8×1024×1024个元器件就是1024KB,简写为1MB;
- 8×1024×1024×1024个元器件就是1024MB,简写为1GB。
现在,你知道1GB的内存有多少个元器件了吧。我们通常所说的文件大小是多少 KB、多少 MB,就是这个意思。
单位换算:
- 1Byte = 8 Bit
- 1KB = 1024Byte = $2^{10}$Byte
- 1MB = 1024KB = $2^{20}$Byte
- 1GB = 1024MB = $2^{30}$Byte
- 1TB = 1024GB = $2^{40}$Byte
- 1PB = 1024TB = $2^{50}$Byte
- 1EB = 1024PB = $2^{6}$Byte
我们平时使用计算机时,通常只会设计到 KB、MB、GB、TB 这几个单位,PB 和 EB 这两个高级单位一般在[大数据](http://c.biancheng.net/big_data/)处理过程中才会用到。
你看,在内存中没有abc这样的字符,也没有gif、jpg这样的图片,只有0和1两个数字,计算机也只认识0和1。所以,计算机使用二进制,而不是我们熟悉的十进制,写入内存中的数据,都会被转换成0和1的组合。
##### 1.2 字符集和字符编码
所谓字符集,就是定义了文字和二进制的对应关系,为字符分配了唯一的编号,通过二进制编号就能找到对应的字符,就类似中英文的查找字典。
而字符编码,就是以何种方式将这些二进制数存进计算机中,以达到节省内存空间或提高查找效率的一种存储方式。之所以称为字符编码,是因为在存储之前必须经过转换,在读取时还要再逆向转换一次,这套转换方案就叫字符编码。
有一些字符集本身也定义了字符编码,比如ASCII码,GBK等,所以他即是字符集,也是字符编码。而Unicode只是一个字符集,只是定义了世界上所有文字对应的二进制数的字典,但对于二进制数如何在计算机中存储并未定义,只是一个单纯的字典。
因此,基于Unicode这个大字典,衍生出了多个编码方式,有UTF-8,UTF-16,UTF-32。
UTF是(Unicode Transformation Format)的缩写,意思是"Unicode转换格式",后面的数字表明至少使用多个个比特位(Bit)来存储字符
**UTF-8**
UTF-8是完全兼容ASCII的,兼容ASCII的含义是,原来ASCII中已经包含的字符,编码值不变,只是在这些字符的后面增添了新的字符
UTF-8的编码规则很简单:
- 如果字符只有一个字节,那么最高的比特位为0,这样可以兼容ASCII。
- 如果字符有多个字节,看字节有多少个比特位,也就是在哪个区间里,就使用哪个区间的
区间如下
- 0xxxxxxx:单字节编码形式,这和ASCII编码完全一样,因此UTF-8是兼容ASCII的
- 110xxxxx 10xxxxxx:双字节编码形式(第一个字节有两个连续的 1);
- 1110xxxx 10xxxxxx 10xxxxxx:三字节编码形式(第一个字节有三个连续的 1)
- 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx:四字节编码形式(第一个字节有四个连续的 1)。
第一个,有7个X,区间为$2^8 - 1$ = 255,换成16进制就是00 - 7F([32]0000 0000 - 0111 1111)
第二个,有11个X,区间为$2^{12} - 1$ = 4096,换成16进制就是080 - 7FF([32] 0000 1000 - [32] 0111 1111 1111)
第三个,有16个X,区间为$2^{16} - 1$ = 65535,换成16进制就是0800 - FFFF,2 进制范围就是
[32]0000 1000 0000 0000 - [32]1111 1111 1111 1111
第四个,有21个X,区间为$2^{22} - 1$ = 4194303,换成16进制就是0001 0000 - 010 FFFF
XXX就用来存储Unicode的字符编号,看编号在哪个范围,不够的前面就用0来补充
[32]0001 0000 0000 0000 0000 - [32]0001 0000 FFFF FFFF FFFF FFFF
下面是一些字符的UTF-8编码实例
| 字符 | 字母N | 符号æ | 中文⻬ |
| ----------------------- | --------------------------------- | ------------------------------------------------------------ | ------------------------------------------------------------ |
| Unicode编号(二进制) | 0100 1110 | 1110 0110 | 0010 1110 1110 1100 |
| Unicode编号(十六进制) | 4E | E6 | 2EEC |
| UTF-8编码(二进制) | 01001110 | 11000011 10100110 | 11100010 10111011 10101100 |
| UTF-8编码(十六进制) | 4E | C3A6 | E2BBAC |
| | | | |
我的做法:首先看这个字符占用几个字节,如果是一个字节,且最高位为0,则直接把这个字符编号当成字符编码存入计算机中,如果有一个字节,但最高位为1,可以,说明有8个X,适合放到区域为11之中,不够的位数前面补0,
**UTF-16**
对于字符编号处于两个字节以内的,不进行编号转换,直接使用两个字节存储。
对于字符编号处于两个字节以上的(0001 0000 0000 0000 0000 - 0000 0100 1111 1111 1111 1111),
UTF-16使用4个字节存储,具体来说,将字符编号的比特位平分成两部分,前面高位的一半比特位用一个值介于(1101 1000 0000 0000 - 1101 1011 1111 1111)D800 - DBFF的双字节存储,后面低位的一半比特位用一个值介于(1101 1100 0000 0000 - 1101 1111 1111 1111 )DC00 - DFFF的双字节存储
| Unicode编号范围(十六进制) | 具体的Unicode编号(二进制) | UTF-16编码 | 编码后的字节数 |
| --------------------------- | --------------------------- | ---------------------------------- | -------------- |
| 0000 0000 - 0000 FFFF | xxxxxxxx xxxxxxxx | xxxxxxxx xxxxxxxx | 2字节 |
| 0001 0000 - 0010 FFFF | yyyy yyyy yy xx xxxx xxxx | 110110yy yyyyyyy 110111xx xxxxxxxx | 4 |
**UTF-32**
UFT-32是固定长度的编码,始终占用4个字节,足以容纳所有的Unicode字符,所以直接存储Unicode编码即可,不需要任何编码转换,浪费了空间,提高了查找效率
**对比以上三种编码方案**
首先,只有UTF-8兼容ASCII,UTF-16和UTF-32都不兼容ASCII,因为这两个没有单字节编码
1)UTF-8使用尽量少的字节来存储一个字符,不但能够节省空间,而且在网络传输中也能节省流量。目前大多数网页如HTML和很多纯文本类型的文件都是用采用UTF-8编码
缺点:UTF-8的缺点是效率低,因为计算机存储的编号是经过转码的,所以对于到Unicode字符集上的编号是错误的,因此还需要解码回正确的Unicode字符,才能找到正确的字符。
例如,要在一个UTF-8编码的字符中找到第10个字符,就得从头开始一个一个的检索字符,这是一个很耗时的过程,因为UTF-8编码的字符串中每个字符占用的字节数不一样,如果不从头遍历每个字符,就不知道第10个字符位于第几个字节处,就无法定位。
2)UTF-32是"以空间换效率",正好弥补了UTF-8的缺点,UTF-32的优势就是效率高,因为UFT-32在读取或者存储的时候都不需要进行编码转换,而且每个字符始终占用4个字节,这样在处理字符串时也能最快速地定位字符。
例如,在一个UTF-32编码的字符串中查找第10个字符,很容易计算出它位于第37个字节处,直接获取就行,不用再逐个遍历字符了,没有比这更快定位字符的方法了。
3)UTF-16可以看做是UTF-8和UTF-32的折中方案,对于两个字节以内的,也不需要进行编码转换,直接存储字符的编码值。
**完全兼容ASCII的编码方案有:UTF-8,GB2312,GBK,GB18030**
**中文编码方案(GB2312,GBK,GB18030)**
GB2312 --> GBK --> GB18030是中文编码的三套方案,出现时间从早到晚,收录的字符数目依此增大且向下兼容。GB2312收录的字符数较少,用1-2个字节存储;GB18030收录的字符最多,用1,2,4个字节存储
| 字符编码 | 说明 |
| -------- | ------------------------------------------------------------ |
| GB2312 | 简体中文字符集,1980年发布,共收录了6763个汉字 |
| GBK | 中文字符集,1995年发布,是在GB2312基础进行的扩展,共收录了21886个汉字,包括GB23212中的全部汉字。 |
| GB18030 | 中文字符集,2000年发布,是对GBK和GB2312的又一个扩展,共收录70244个汉字 |
GB2312和GBK编码方式:
1)从整体上讲,CB2312和GBK的编码方式一致,具体为:
- 对于ASCII字符,使用一个字节存储,并且该字节的最高位是0,这和ASCII编码是一致的,所以说GB2312完全兼容ASCII。
- 对于中国的字符,使用两个字节存储,且规定每个字节的最高为都是1。
例如对于字母A,他在内存中存储为01000001,对于汉字`中`,它在内存中存储为11010110 11010000
这样规定的好处就是,由于单字节和双字节的最高位不一样,所以字符处理软件可以根据这一特点区分一个字符到底是用了几个字节。
2)GB2312为了容纳更多的字符,并且要区分两个字节和四个字节,所以修改了编码方案,具体为:
- 对于ASCII字符,使用一个字节存储,并且该字节的最高位是0,这和ASCII,GB2312,GBK编码是一致的
- 对于常用的中文字符,使用两个字节存储,并且规定第一个字节的最高位是1,第二个字节可以是0或1,但为0时次高位就不能为0(对比GB2312和GBK,他们要求两个字节的最高位都必须是 1)
- 对于罕见的字符,使用四个字节存储,并且规定第一个和第三个字节的最高位是1,第二个和第四个字节的高位必须有两个连续的0.
例如对于对于字母A,他在内存中存储为01000001,对于汉字`中`,它在内存中存储为11010110 11010000,对于藏文 `,`,它在内存中的存储为10000001 00110010 11101111 00110000。
字符处理软件在处理文本时,从左往右依次扫描每个字节:
1. 如果遇到的字节的最高位是0,那么就会断定该字符只占用了一个字节;
2. 如果遇到的字节的最高位是1,那么该字符可能占用了两个字节,也可能占用了四个字节,不能妄下结论,所以还要继续扫描;
3. 如果第二个字节的最高位有两个连续的0,那么就会断定改字符占用了四个字节;
4. 如果第二个字节的最高位没有连续的0,那么就会断定该字符占用了两个字节
可见,当字符占用两个或四个字节时,GB18030编码要检测两次,处理效率比GB2312和GBK都低。
**总结:**
- ASCII是单字符编码,即是字符集,也是字符编码,它的编码方式就是没有,直接把字符对应的二进制数存入计算机内存中
- 常见兼容ASCII编码的字符编码有:UTF-8,GB2312,GBK,GB18030
- 中文的三种字符编码,如果字符只有一个字节且最高位不为1,都遵循ASCII编码规范,如果两个或四个字节,(GB2312,GBK,BG18030)这三种编码的最高位都是1,仅凭这样无法判断是两个字节还是四个字节,就要看第二个字节的高2 位是否存在两个连续的00,如果存在连续的00,则是四个字节,如果第二个字节的最高位没有连续的0,那么就会断定该字符占用了两个字节。
- UTF-8对于字符如果也只有一个字节且最高位不为1,采用ASCII编码规范,如果比特位是8且最高位是1或比特位小于11个则采用双字节编码,如果比特位大于11