# treasure-map
**Repository Path**: cxylk/treasure-map
## Basic Information
- **Project Name**: treasure-map
- **Description**: No description available
- **Primary Language**: Java
- **License**: Not specified
- **Default Branch**: main
- **Homepage**: None
- **GVP Project**: No
## Statistics
- **Stars**: 0
- **Forks**: 0
- **Created**: 2021-12-19
- **Last Updated**: 2022-11-14
## Categories & Tags
**Categories**: Uncategorized
**Tags**: None
## README
treasure-map
## 1、javaagent插桩机制
对应代码为项目中的`javaagent`模块
## 2、ClassLoader问题
这部分中,我们简单的写了个查询数据库的方法,然后对该方法进行插桩,插桩的入口是`BaseExecutor`,方法是第二个query方法,也就是参数最多的那个方法。接下来分析其中遇到的问题:
#### BaseExecutor找不到
在第一个版本中,代码见`agent1`项目的`MybatisAgent1`类,然后在`boot-example`这个spring-boot项目中启动,此时会报`BaseExecutor`这个类找不到,原因是这样的:
~~~Java
ClassPool classPool=new ClassPool();
//加入系统路径
classPool.appendSystemPath();
~~~
新建了一个类池,并且给这个类池一个系统的路径来加载类,但是这个系统路径它加载的是rt,ext这些路径下的类,而我们导入的mybatis相关的jar包是通过appClassloader来加载的,我们知道,jvm中的类加载机制,父类是访问不了子类的,也就是访问不了`BaseExecutor`,解决的办法就是将加载它的类加载器也放入到类池路径下:
~~~Java
classPool.appendClassPath(new LoaderClassPath(loader));
~~~
这个loader就是transform方法的第一个参数loader。
#### BoundSql找不到
我们先来看下代码:
~~~Java
public static SqlInfo begin(Object[] args){
SqlInfo sqlInfo=new SqlInfo();
sqlInfo.setBeginTime(System.currentTimeMillis());
//获取执行的SQL,BoundSql是query的第6个参数(从0开始)
BoundSql boundSql=(BoundSql)args[5];
sqlInfo.setSql(boundSql.getSql());
//获取SQL参数,query的第2个参数
Object para=args[1];
sqlInfo.setParameter(para);
return sqlInfo;
}
~~~
可以看到,我们通过插桩方法`query`的参数获取到了BoundSql,然后调用了它的getSql方法。
然后启动spring-boot应用,我们通过两种方式来启动:
##### 直接在idea里面启动
这种方式是不会报错的,因为这种方式的类加载结构如下:
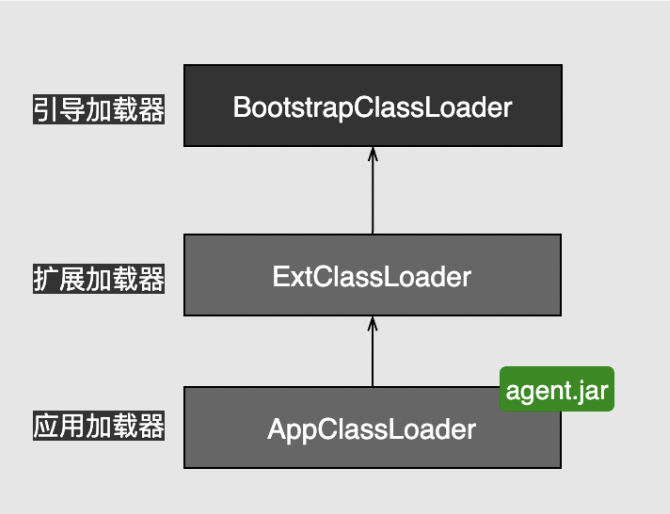
可以看到,在idea中是直接以`ApplicationClassLoader`来load的,此时agent.jar包和spring-boot应用是在同一层,所以这种方式是不会报错的。
##### 通过-jar的方式启动
我们在spring-boot应用的pom文件中加入以下依赖:
~~~xml
org.springframework.boot
spring-boot-maven-plugin
2.6.5
repackage
~~~
这种方式打包和普通方式打包的不同可以看这篇文章:https://blog.csdn.net/yu102655/article/details/112490962
我们看打包后的jar包结构:
~~~
boot-example
├── BOOT-INF
│ ├── classes(我们写的程序)
│ │ ├── application.properties
│ │ └── com
│ │ └── cxylk
│ │ ├── BootExampleApplication.class
│ │ ├── bean
│ │ │ └── User.class
│ │ ├── controller
│ │ │ └── MyController.class
│ │ ├── dao
│ │ │ └── UserMapper.class
│ │ └── service
│ │ ├── UserService.class
│ │ └── UserServiceImpl.class
│ └── lib(当前程序依赖的第三方jar)
│ ├── HikariCP-3.4.5.jar
│ ├── jackson-annotations-2.13.2.jar
│ ├── jackson-core-2.13.2.jar
│ ├── jackson-databind-2.13.2.jar
│ ├── jackson-datatype-jdk8-2.13.2.jar
│ ├── jackson-datatype-jsr310-2.13.2.jar
│ ├── jackson-module-parameter-names-2.13.2.jar
│ ├── jakarta.annotation-api-1.3.5.jar
│ ├── jul-to-slf4j-1.7.36.jar
│ ├── log4j-api-2.17.2.jar
│ ├── log4j-to-slf4j-2.17.2.jar
│ ├── logback-classic-1.2.11.jar
│ ├── logback-core-1.2.11.jar
│ ├── mybatis-3.5.6.jar
│ ├── mybatis-spring-2.0.6.jar
│ ├── mybatis-spring-boot-autoconfigure-2.1.4.jar
│ ├── mybatis-spring-boot-starter-2.1.4.jar
│ ├── mysql-connector-java-8.0.15.jar
│ ├── protobuf-java-3.6.1.jar
│ ├── slf4j-api-1.7.30.jar
│ ├── snakeyaml-1.29.jar
│ ├── spring-aop-5.3.17.jar
│ ├── spring-beans-5.3.17.jar
│ ├── spring-boot-2.6.5.jar
│ ├── spring-boot-autoconfigure-2.6.5.jar
│ ├── spring-boot-jarmode-layertools-2.6.5.jar
│ ├── spring-context-5.3.17.jar
│ ├── spring-core-5.3.17.jar
│ ├── spring-expression-5.3.17.jar
│ ├── spring-jcl-5.3.17.jar
│ ├── spring-jdbc-5.3.1.jar
│ ├── spring-tx-5.3.1.jar
│ ├── spring-web-5.3.17.jar
│ ├── spring-webmvc-5.3.17.jar
│ ├── tomcat-embed-core-9.0.60.jar
│ ├── tomcat-embed-el-9.0.60.jar
│ └── tomcat-embed-websocket-9.0.60.jar
├── META-INF(应用相关的元信息)
│ ├── MANIFEST.MF
│ └── maven
│ └── com.cxylk
│ └── boot-example
│ ├── pom.properties
│ └── pom.xml
└── org(jar加载和启动相关的类)
└── springframework
└── boot
└── loader
├── ClassPathIndexFile.class
├── ExecutableArchiveLauncher.class
├── JarLauncher.class
├── LaunchedURLClassLoader$DefinePackageCallType.class
├── LaunchedURLClassLoader$UseFastConnectionExceptionsEnumeration.class
├── LaunchedURLClassLoader.class
├── Launcher.class
├── MainMethodRunner.class
├── PropertiesLauncher$1.class
├── PropertiesLauncher$ArchiveEntryFilter.class
├── PropertiesLauncher$ClassPathArchives.class
├── PropertiesLauncher$PrefixMatchingArchiveFilter.class
├── PropertiesLauncher.class
├── WarLauncher.class
├── archive
│ ├── Archive$Entry.class
│ ├── Archive$EntryFilter.class
│ ├── Archive.class
│ ├── ExplodedArchive$AbstractIterator.class
│ ├── ExplodedArchive$ArchiveIterator.class
│ ├── ExplodedArchive$EntryIterator.class
│ ├── ExplodedArchive$FileEntry.class
│ ├── ExplodedArchive$SimpleJarFileArchive.class
│ ├── ExplodedArchive.class
│ ├── JarFileArchive$AbstractIterator.class
│ ├── JarFileArchive$EntryIterator.class
│ ├── JarFileArchive$JarFileEntry.class
│ ├── JarFileArchive$NestedArchiveIterator.class
│ └── JarFileArchive.class
├── data
│ ├── RandomAccessData.class
│ ├── RandomAccessDataFile$1.class
│ ├── RandomAccessDataFile$DataInputStream.class
│ ├── RandomAccessDataFile$FileAccess.class
│ └── RandomAccessDataFile.class
├── jar
│ ├── AbstractJarFile$JarFileType.class
│ ├── AbstractJarFile.class
│ ├── AsciiBytes.class
│ ├── Bytes.class
│ ├── CentralDirectoryEndRecord$1.class
│ ├── CentralDirectoryEndRecord$Zip64End.class
│ ├── CentralDirectoryEndRecord$Zip64Locator.class
│ ├── CentralDirectoryEndRecord.class
│ ├── CentralDirectoryFileHeader.class
│ ├── CentralDirectoryParser.class
│ ├── CentralDirectoryVisitor.class
│ ├── FileHeader.class
│ ├── Handler.class
│ ├── JarEntry.class
│ ├── JarEntryCertification.class
│ ├── JarEntryFilter.class
│ ├── JarFile$1.class
│ ├── JarFile$JarEntryEnumeration.class
│ ├── JarFile.class
│ ├── JarFileEntries$1.class
│ ├── JarFileEntries$EntryIterator.class
│ ├── JarFileEntries$Offsets.class
│ ├── JarFileEntries$Zip64Offsets.class
│ ├── JarFileEntries$ZipOffsets.class
│ ├── JarFileEntries.class
│ ├── JarFileWrapper.class
│ ├── JarURLConnection$1.class
│ ├── JarURLConnection$JarEntryName.class
│ ├── JarURLConnection.class
│ ├── StringSequence.class
│ └── ZipInflaterInputStream.class
├── jarmode
│ ├── JarMode.class
│ ├── JarModeLauncher.class
│ └── TestJarMode.class
└── util
└── SystemPropertyUtils.class
~~~
spring boot使用了这种**FatJar**技术将所有依赖放在一个最终的jar包文件BOOT-INF/lib中,把当前项目的class全部放在BOOT-INF/classes目录中。并且在lib中可以看到`tomcat-embed-core-9.0.60.jar`这个Tomcat的启动包,spring boot内置的Tomcat就是这样加载到项目中的。
我们再来看下MANIFEST文件中的内容:
~~~
Manifest-Version: 1.0
Spring-Boot-Classpath-Index: BOOT-INF/classpath.idx
Archiver-Version: Plexus Archiver
Built-By: likui
Spring-Boot-Layers-Index: BOOT-INF/layers.idx
Start-Class: com.cxylk.BootExampleApplication
Spring-Boot-Classes: BOOT-INF/classes/
Spring-Boot-Lib: BOOT-INF/lib/
Spring-Boot-Version: 2.6.5
Created-By: Apache Maven 3.8.4
Build-Jdk: 1.8.0_311
Main-Class: org.springframework.boot.loader.JarLauncher
~~~
这里面有两个重要参数:
1、Start-Class:
它是应用自己的main函数,这个参数对应的类才是真正的业务main函数入口
2、Main-Class:
它是org.springframework.boot.loader.JarLauncher,它是这个jar包启动的main函数,**它负责创建LaunchedURLClassLoader来加载/lib下面所有的jar包**。我们可以看下相关的核心代码,就在上面解压后的loader目录下:
~~~Java
public static void main(String[] args) throws Exception {
(new JarLauncher()).launch(args);
}
~~~
最终会调用到基类`Launcher`中的`launch`方法:
~~~Java
protected void launch(String[] args) throws Exception {
if (!this.isExploded()) {
JarFile.registerUrlProtocolHandler();
}
ClassLoader classLoader = this.createClassLoader(this.getClassPathArchivesIterator());
String jarMode = System.getProperty("jarmode");
String launchClass = jarMode != null && !jarMode.isEmpty() ? "org.springframework.boot.loader.jarmode.JarModeLauncher" : this.getMainClass();
this.launch(args, launchClass, classLoader);
}
~~~
该方法分为三步:
(1)注册URL协议并清除应用缓存
(2)创建类加载器
~~~Java
protected ClassLoader createClassLoader(URL[] urls) throws Exception {
return new LaunchedURLClassLoader(isExploded(), getArchive(), urls, getClass().getClassLoader());
}
~~~
可以发现这里创建了一个新的classloader,也就是**LaunchedURLClassLoader**,然后将classload加入thread的context中:
~~~Java
protected void launch(String[] args, String launchClass, ClassLoader classLoader) throws Exception {
Thread.currentThread().setContextClassLoader(classLoader);
createMainMethodRunner(launchClass, args, classLoader).run();
}
~~~
LaunchedURLClassLoader继承了URLClassloader,并且实现了loadClass方法,这其实又回到了双亲委派机制,最后让Application Classloader来load。这里的第二个参数也就是要加载的类通过下面这个方法得到:
~~~Java
protected String getMainClass() throws Exception {
Manifest manifest = this.archive.getManifest();
String mainClass = null;
if (manifest != null) {
mainClass = manifest.getMainAttributes().getValue("Start-Class");
}
if (mainClass == null) {
throw new IllegalStateException("No 'Start-Class' manifest entry specified in " + this);
} else {
return mainClass;
}
}
~~~
可以看到,它就是定义的start-class,也就是我们实际在代码中启动的类
(3)执行main方法
在MainMethodRunner中,通过LauncherdURLClassLoader load并且通过反射调用了start-class参数对应的类中的main方法:
~~~Java
public void run() throws Exception {
Class mainClass = Class.forName(this.mainClassName, false, Thread.currentThread().getContextClassLoader());
Method mainMethod = mainClass.getDeclaredMethod("main", String[].class);
mainMethod.setAccessible(true);
mainMethod.invoke((Object)null, this.args);
}
~~~
所以,通过FAT JAR的方式启动jar包,这时的类加载就是下面所示:
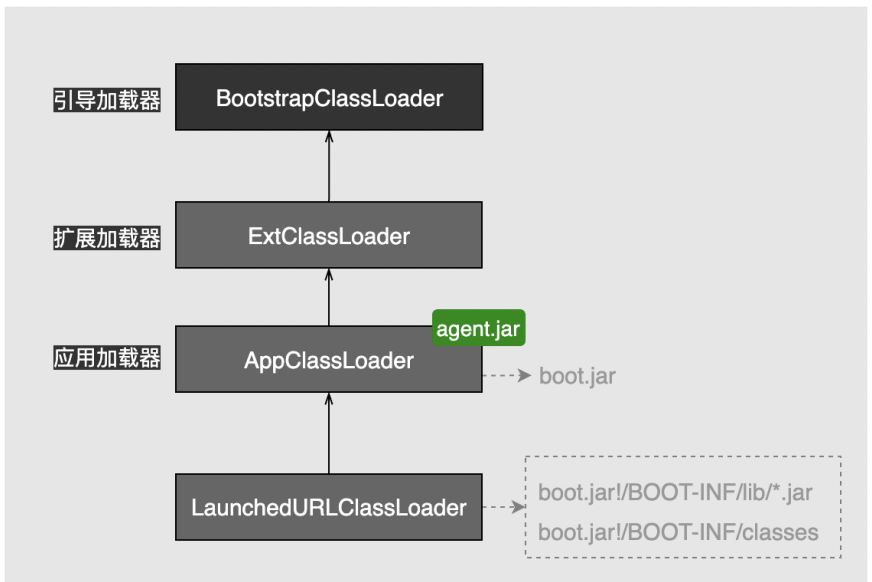
##### 原因
那么现在,我们就知道为什么通过jar的方式启动会提示找不到BoundSql了:
BoundSql是我们导入mybatis依赖才会有的,而mybatis依赖包在我们将应用打成jar包后,它位于BOOT-INF/lib下面(从上面的jar包结构中可以找到),由LaunchedURLClassLoader加载,而我们的agent jar包是由它的父类AppClassLoader来加载的,现在,agent jar包中的begin方法要去访问它的子类加载的mybatis相关类,当然会提示找不到,因为子类可以访问父类,但是父类是访问不了子类的!
#### 解决办法
两种解决办法:
1、将位于AppClassLoader这层的agent.jar包放入到下面的LaunchedURLClassLoader中:
~~~Java
public void appendToLoader(ClassLoader loader) throws NoSuchMethodException, MalformedURLException, InvocationTargetException, IllegalAccessException {
URLClassLoader urlClassLoader= (URLClassLoader) loader;
Method method = URLClassLoader.class.getDeclaredMethod("addURL", URL.class);
method.setAccessible(true);
String path = MybatisAgent2.class.getResource("").getPath();//file:/Users/likui/Workspace/github/treasure-map/agent1/target/agent1-0.0.1-SNAPSHOT.jar!/com/cxylk/agent1/mybatis/
path=path.substring(0,path.indexOf("!/"));
//调用addURL方法将MybatisAgent2的类路径加入到URLClassloader中
method.invoke(urlClassLoader,new URL(path));
}
~~~
但是这种方式在Tomcat中可行,使用-jar的方式还是会报错
2、**通过适配器反射**
这种方式是最合适也是最推荐的,这样就不用担心到底是通过-jar的方式启动还是Tomcat方式启动,原理就是在父类加载器访问子类加载器的时候不是直接访问子类加载器,而是给父类添加一个适配器,然后通过反射的方式来访问子类加载器相关的类:
~~~Java
public static class BoundSqlAdapter{
private Object target;
private Class aClass;
private Method getSql;
public BoundSqlAdapter(Object target){
this.target=target;
if(this.aClass==null){
init(target.getClass());
}
}
private synchronized void init(Class clazz){
try {
aClass=clazz;
getSql=clazz.getDeclaredMethod("getSql");
getSql.setAccessible(true);
} catch (Exception e) {
e.printStackTrace();
}
}
public String getSql(){
try {
return (String) getSql.invoke(target);
} catch (Exception e) {
throw new RuntimeException(e);
}
}
}
~~~
将原来直接访问BoundSql的地方替换为BoundSqlAdapter,然后通过构造函数传入一个Object,比如要访问的是BoundSql,**那么这里就是一个以Object表示的BoundSql**,不能直接写BoundSql,不然还是会提示找不到。
## 3、HTTP协议监控
### 3.1、服务响应监控
#### 设计目标
http采集的目标:
1、保证稳定性:系统运行时,一直都可以采集数据
2、保证通用性:尽可能支持更多的http服务实现
3、实现简单:减少开发维护成本
#### 插桩采集点
http服务的实现整体是由Servlet容器提供的,如Tomcat,Jetty,Netty。
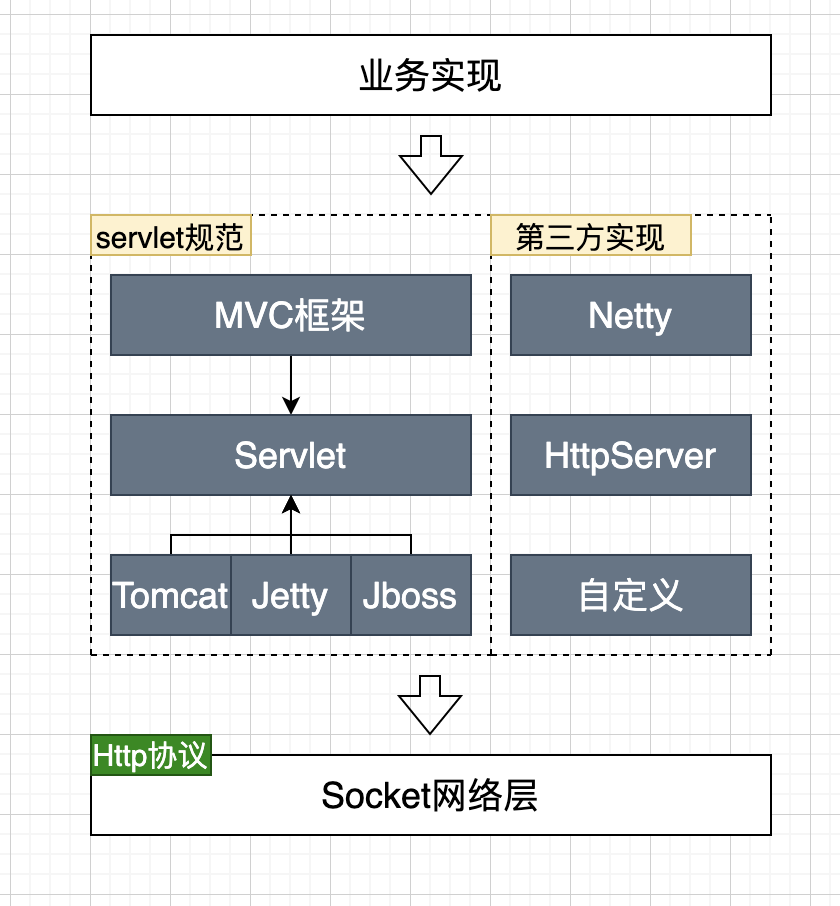
Http服务实现分为两部分,一种是支持Servlet规范的,另一种是不支持Servlet规范的第三方实现,绝大部分业务都是基于第一种实现的,所以不支持Servlet规范的基本先不考虑。在Servlet规范这边,又划分成MVC框架层,Servlet层,容器层,除了中间层Servlet层其它两层的实现都是多样的,所以**为了保证通用性在Servlet层插桩是最佳选择**。比如使用MVC框架,DispatchServlet也是实现HttpServlet的,最终还是调用的HttpServlet。
#### 采集数据
1、URL路径
2、客户端IP
3、请求完整用时
4、请求参数
5、异常信息
#### ClassLoader问题
在begin方法中,需要获取service方法的第一个参数`HttpServletRequest`得到URL等信息,这样在使用jar包启动时任然会报错,和上面分析的一样。
我们先来看Tomcat的类加载器结构:

* Common通用类加载器加载Tomcat使用以及应用通用的一些类,位于CATALINA_HOME/lib下,**比如servlet-api.jar**。
* Catalina ClassLoader ⽤于加载服务器内部可⻅类,这些类应⽤程序不能访问
* SharedClassLoader ⽤于加载应⽤程序共享类,这些类服务器不会依赖
* WebappClassLoader,每个应⽤程序都会有⼀个独⼀⽆⼆的Webapp ClassLoader,他⽤来加载本应⽤程序 /WEB-INF/classes 和 /WEB-INF/lib 下的类
前面分析过,agent.jar是AppClassLoader加载的,而servlet jar包是Tomcat的Common类加载器加载的,它是AppClassLoader的子类,这样在启动web应用时,父类中的agent要访问子类下的servlet中相关的类,肯定是访问不到的(启动的是web应用,访问的类都是以web应用中的类为准)。
解决办法,仍然是通过适配器来解决,具体看代码agent1模块下的httpserver包下的HttpCollect类。
### 3.2、服务调用监控
与前面所说的Http响应进入到我们服务相反,现在要实现的是通过http调用别人的服务
#### Http API调用方式
##### 基于URL直接调用
##### 基于工具调用
##### 基于第三方平台提供的SDK来调用
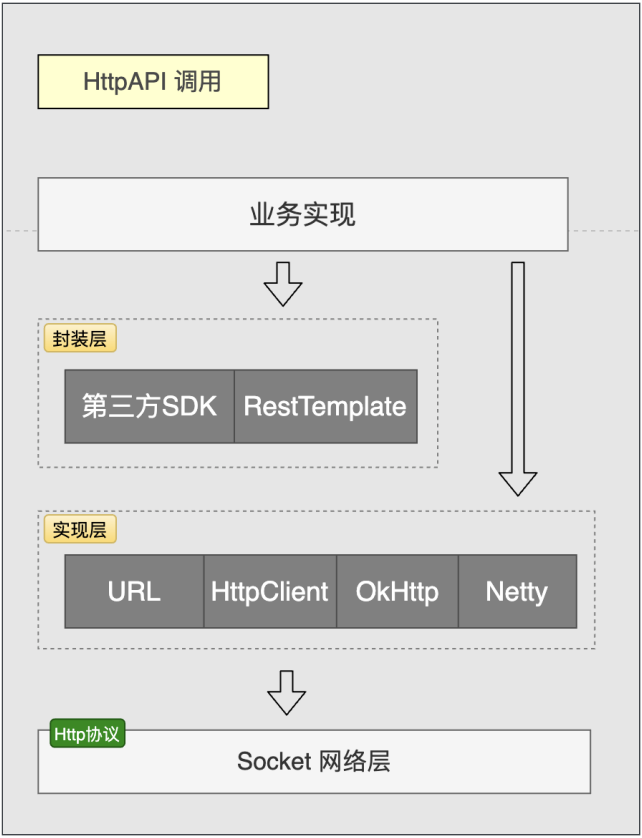
可以发现,Http调用实现并没有集中的点,只能针对这些框架一个个实现采集插桩,并且封装层在实际使用中并不多,主要还是实现层,所以根据通用程度先实现URL采集监控。
#### URL Http调用分析
基于URL http的调用,一般都是下面这段代码来实现:
~~~java
//构造一个URL
URL url = new URL("https://www.baidu.com");
//创建网络连接
URLConnection conn = url.openConnection();
//打开连接
conn.connect();
//读取流
InputStream input = conn.getInputStream();
byte[] bytes = IOUtils.readFully(input, -1, false);
System.out.println(new String(bytes));
~~~
这种方式很难一眼就能找到监控点,这时就必须深入URL的内部实现:
~~~java
public URLConnection openConnection() throws java.io.IOException {
return handler.openConnection(this);
}
~~~
在建立网络连接中,是通过调用handler的openConnection方法完成的,那么这个handler是什么呢?
~~~java
transient URLStreamHandler handler;
~~~
它是一个协议处理器,来处理不同协议的URL,比如http,https,ftp等等,它是一个抽象类,不同的协议有不同的实现,而我们在第一步构造URL时传进来的url中会有具体的协议,然后在构造函数中就会得到对应协议的URLStreamHandler,这部分代码省略。所以我们来看https的实现,需要注意的是**这些处理器都叫Handler,只不过协议的不同,它的包前缀不同**,比如https的就是`sun.net.www.protocol.https`下的Handler,http的就是`sun.net.www.protocol.http`下的Handler。
~~~java
public class Handler extends sun.net.www.protocol.http.Handler {
protected String proxy;
protected int proxyPort;
protected int getDefaultPort() {
return 443;
}
public Handler() {
this.proxy = null;
this.proxyPort = -1;
}
public Handler(String var1, int var2) {
this.proxy = var1;
this.proxyPort = var2;
}
protected URLConnection openConnection(URL var1) throws IOException {
return this.openConnection(var1, (Proxy)null);
}
protected URLConnection openConnection(URL var1, Proxy var2) throws IOException {
return new HttpsURLConnectionImpl(var1, var2, this);
}
}
~~~
https对应的Handler继承了http对应的Handler,可以看到,openConnection这个方法中返回的是HttpsURLConnectionImpl,它是HttpsURLConnection中的内部类,这里有点绕,我们直接看http协议对应的Handler:
~~~Java
package sun.net.www.protocol.http;
public class Handler extends URLStreamHandler {
protected String proxy;
protected int proxyPort;
protected int getDefaultPort() {
return 80;
}
public Handler() {
this.proxy = null;
this.proxyPort = -1;
}
public Handler(String var1, int var2) {
this.proxy = var1;
this.proxyPort = var2;
}
protected URLConnection openConnection(URL var1) throws IOException {
return this.openConnection(var1, (Proxy)null);
}
protected URLConnection openConnection(URL var1, Proxy var2) throws IOException {
return new HttpURLConnection(var1, var2, this);
}
}
~~~
这个HttpURLConnection是`sun.net.www.protocol.http`包下的,但是它继承了`java.net`包下的HttpURLConnection,父类HttpURLConnection就是url.openConnection返回的Connection,但是建立连接connect这个方法还是在`sun.net.www.protocol.http`这个包下的HttpURLConnection来实现的。
我们来看下这个流程:
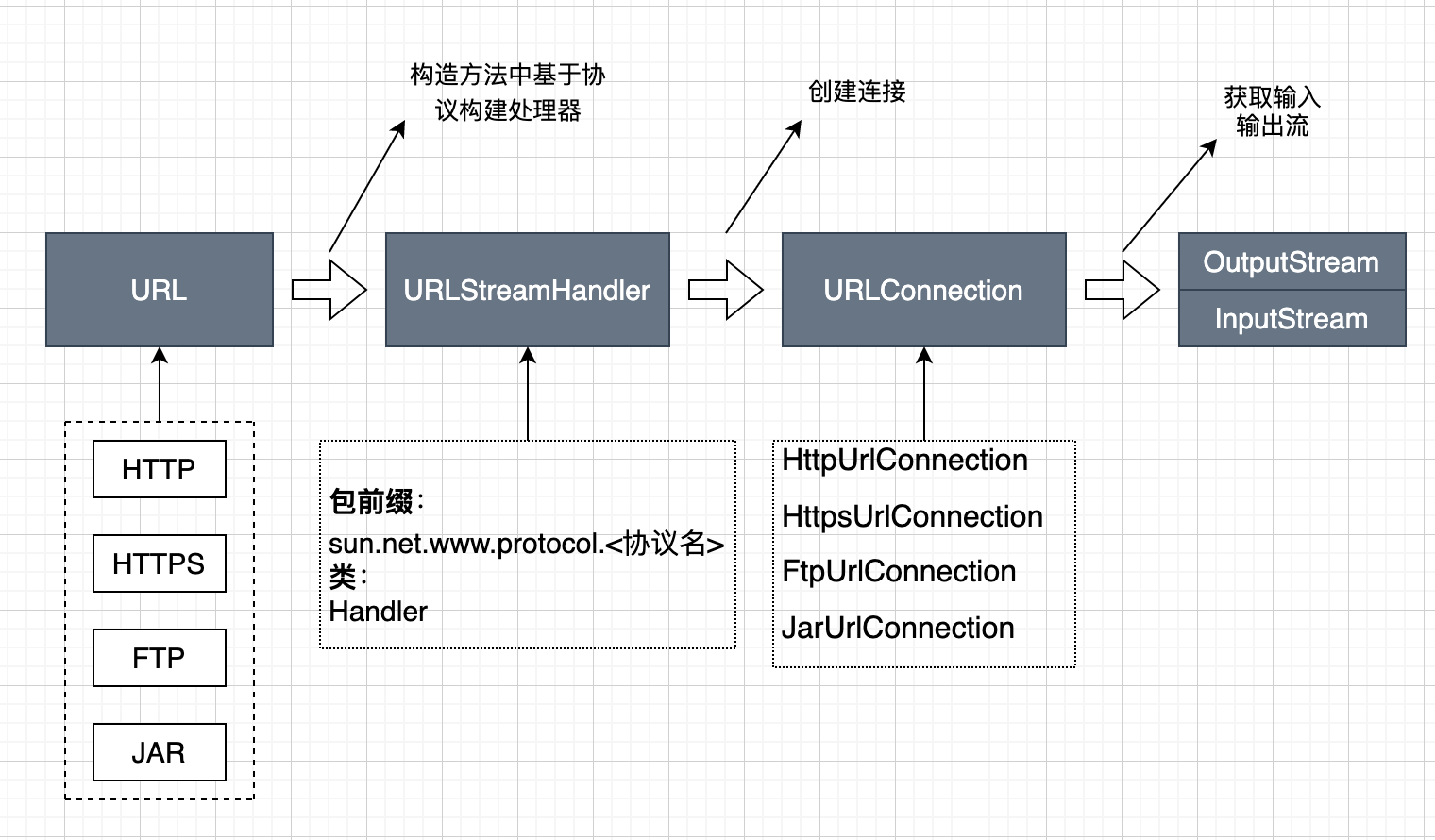
所以我们只要在源头去控制处理器的生成,就可以从头到尾代理整个URL的处理过程,并获取性能数据。
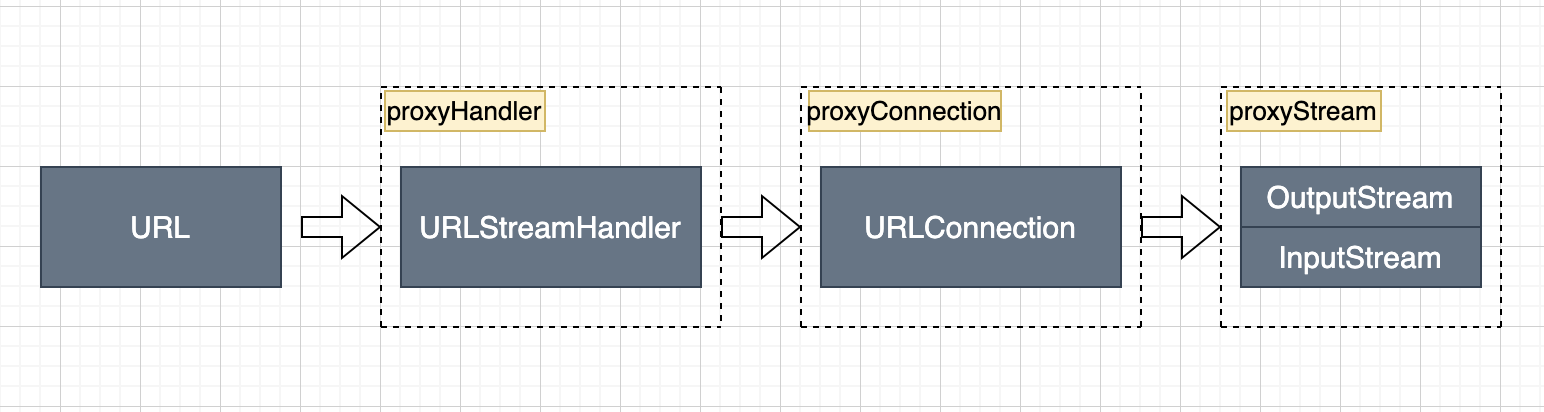
构建处理器有下面几种方式,优先级由高到低
##### 基于自定义的URLStreamHandlerFactory
我们看下URL的构造函数就知道了:
~~~java
public URL(String protocol, String host, int port, String file,
URLStreamHandler handler) throws MalformedURLException {
...
if (handler == null &&
(handler = getURLStreamHandler(protocol)) == null) {
throw new MalformedURLException("unknown protocol: " + protocol);
}
this.handler = handler;
}
~~~
getURLStreamHandler方法会根据不同的协议得到对应的URLStreamHandler:
~~~Java
static URLStreamHandler getURLStreamHandler(String protocol) {
URLStreamHandler handler = handlers.get(protocol);
if (handler == null) {
boolean checkedWithFactory = false;
// Use the factory (if any)
if (factory != null) {
handler = factory.createURLStreamHandler(protocol);
checkedWithFactory = true;
}
//后面的代码还会将
...
~~~
可以看到,如果factory不为空的话,那么直接根据factory的createURLStreamHandler创建处理器,**所以我们就可以对这个factory代理,然后重写createURLStreamHandler方法,根据不同的协议实现不同的Handler**。factory在URL中也提供了设置的入口:
~~~java
public static void setURLStreamHandlerFactory(URLStreamHandlerFactory fac) {
synchronized (streamHandlerLock) {
if (factory != null) {
throw new Error("factory already defined");
}
SecurityManager security = System.getSecurityManager();
if (security != null) {
security.checkSetFactory();
}
handlers.clear();
factory = fac;
}
}
~~~
我们只要调用这个方法,参数传入代理后的URLStreamHandlerFactory即可。
而url.openConnection方法返回的也是我们通过代理HttpUrlConnection得到的对象,然后在执行connect,disconnect时就可以插桩了,比如连接建立时间等,具体看代码agent1模块下httpinvoker包下的HttpProxy1和ProxyHttpUrlConnection。
**但是需要注意**:在上面这个方法中可以发现,如果factory!=null,那么会报错的,而事实也证明如此,不管是通过idea直接运行web项目还是通过jar的方式,因为factory我们在Tomcat启动前已经自己实现了一个代理类进行初始化,**但是Tomcat它也会创建这个factory,所以导致factory被初始化了两次**:
~~~Java
private TomcatURLStreamHandlerFactory(boolean register) {
this.registered = register;
if (register) {
URL.setURLStreamHandlerFactory(this);
}
}
~~~
也就是说这种方式如果servlet容器是Tomcat的话是行不通的。
##### 基于⾃定义包前缀获取:java.protocol.handler.pkgs
我们再回过头来看getURLStreamHandler这个方法:
~~~Java
static URLStreamHandler getURLStreamHandler(String protocol) {
URLStreamHandler handler = handlers.get(protocol);
if (handler == null) {
boolean checkedWithFactory = false;
// Use the factory (if any)
if (factory != null) {
handler = factory.createURLStreamHandler(protocol);
checkedWithFactory = true;
}
// Try java protocol handler
if (handler == null) {
String packagePrefixList = null;
//根据java.protocol.handler.pkgs得到包前缀,默认是空
packagePrefixList
= java.security.AccessController.doPrivileged(
new sun.security.action.GetPropertyAction(
protocolPathProp,""));
if (packagePrefixList != "") {
packagePrefixList += "|";
}
// REMIND: decide whether to allow the "null" class prefix
// or not.
packagePrefixList += "sun.net.www.protocol";
StringTokenizer packagePrefixIter =
new StringTokenizer(packagePrefixList, "|");
while (handler == null &&
packagePrefixIter.hasMoreTokens()) {
String packagePrefix =
packagePrefixIter.nextToken().trim();
try {
//只需在packagePrefixList中也加入一个我们自定义的packagePrefix即可,其余不变
String clsName = packagePrefix + "." + protocol +
".Handler";
Class cls = null;
try {
cls = Class.forName(clsName);
} catch (ClassNotFoundException e) {
ClassLoader cl = ClassLoader.getSystemClassLoader();
if (cl != null) {
cls = cl.loadClass(clsName);
}
}
if (cls != null) {
handler =
(URLStreamHandler)cls.newInstance();
}
} catch (Exception e) {
// any number of exceptions can get thrown here
}
}
}
...
~~~
当factory为空后,首先通过这个方法GetPropertyAction,其中参数protocolPathProp = "java.protocol.handler.pkgs";:
~~~Java
private String theProp;
private String defaultVal;
public GetPropertyAction(String var1) {
this.theProp = var1;
}
//构造方法赋值
public GetPropertyAction(String var1, String var2) {
this.theProp = var1;
this.defaultVal = var2;
}
//放入系统属性中
//Key就是java.protocol.handler.pkgs,value默认是空
public String run() {
String var1 = System.getProperty(this.theProp);
return var1 == null ? this.defaultVal : var1;
}
~~~
然后后面在包前缀列表packagePrefixList中又加入了"sun.net.www.protocol"这个包,多个包是通过|来分隔的,然后根据包前缀+协议+Handler得到className,再通过反射生成URLStreamHandler,所以我们也可以模仿这种方式:**自定义包前缀,然后根据自定义包前缀+协议+Handler放入系统属性中,key还是java.protocol.handler.pkgs不变**。
比如我们在com.cxylk.agent1.httpinvoker.https(代理的是哪个协议,这个包名就是对应协议的名称)这个包下定义Handler类
~~~Java
public class Handler extends sun.net.www.protocol.https.Handler {
@Override
protected URLConnection openConnection(URL url, Proxy proxy) throws IOException {
HttpURLConnection connection = (HttpURLConnection) super.openConnection(url, proxy);
return new ProxyHttpUrlConnection(connection, url);
}
@Override
protected URLConnection openConnection(URL url) throws IOException {
return openConnection(url, null);
}
}
~~~
然后将Handler所在的包加入系统属性中:
```
public class HttpProxy2 {
private static final String PROTOCOL_HANDLER = "java.protocol.handler.pkgs";
private static final String HANDLERS_PACKAGE="com.cxylk.agent1.httpinvoker";
public static void registerProtocol(){
String handlers = System.getProperty(PROTOCOL_HANDLER, "");
//handlers不为空的话,还要加上handlers,使用|拼接
System.setProperty(PROTOCOL_HANDLER,(handlers==null||handlers.isEmpty())?HANDLERS_PACKAGE:handlers+"|"+HANDLERS_PACKAGE);
}
}
```
最后在premain方法中调用registerProtocol方法即可。
## 4、JDBC监控
我们都知道一个SQL执行的逻辑为:SQL请求-->jdbc temlate或orm框架-->jdbc-->data source-->driver-->db,
为了**不对使用场景做假设**,屏蔽框架和不同数据库厂商驱动带来的差异,我们选择在jdbc这层做插桩。但是在Java中,driver只是一个规范,其实现是由不同的数据库厂商决定的,所以我们需要针对不同的厂商进行单独插桩,比如以MySQL来说,真正获取connect的是`NonRegisteringDriver`这个类,所以我们对这个类的`connect`进行插桩后,能拿到`Connection`对象,然后我们需要对它进行动态代理,从而实现我们的监控逻辑,同理,通过它可以继续拿到`PreparedStatement`,继续进行动态代理,代理的目的依然是实现我们的监控逻辑,通过它就可以得到执行的SQL,参数等信息。
## 5、Redis监控
Redis有两种客户端,jedis和lettuce,不同的客户端需要做不同的监控处理,比如jedis,它的执行逻辑就是不管是get还是set等命令,最后都是通过`Protocol`类的`sendCommand`方法到Redis服务端,所以我们需要监控这个方法,这样可以得到开始时间和执行的命令等信息。而返回结果是通过`process`这个方法得到的,所以我们插桩这个方法就可以得到结果信息。
## 6、Agent整体设计
将service、http、sql等信息采集统一成一套规范。
#### 模块分包
**base模块**:定义采集接口、处理接口,以及采集会话,插桩入口实现
**model数据模块**:定义采集的数据模型,包括http指标、sql指标、service指标
**collect采集器模块**:采集功能的具体实现,包括http采集器、jdbc采集器、service采集器
**process处理器模块**:处理器功能的具体实现,比如JSON序列化,日志处理,基本信息处理(调用链ID,当前的采集方式)
**common基础支持模块**:JSON序列化(这里采用的是GitHub上的一款轻量级日志框架json-io,地址:https://github.com/jdereg/json-io),日志打印(采用JDK自带的日志框架,日志输出目录默认为agent target目录,可自行配置)。
#### 会话功能
一个业务请求通常会涉及多个SQL调用、多个服务调用,监控系统需要能统一辨别,而不是分散 的日志。这就需要一个统一的ID将日志进行关联,相同的ID表示所属同一请求。具体做法是在请 求入服务器时生成一个ID,并保存在线程本地变量(ThreadLocal)中,在该线程下所有日志 要取 出该ID并关联,当请求结束后在删除该ID。
实现:
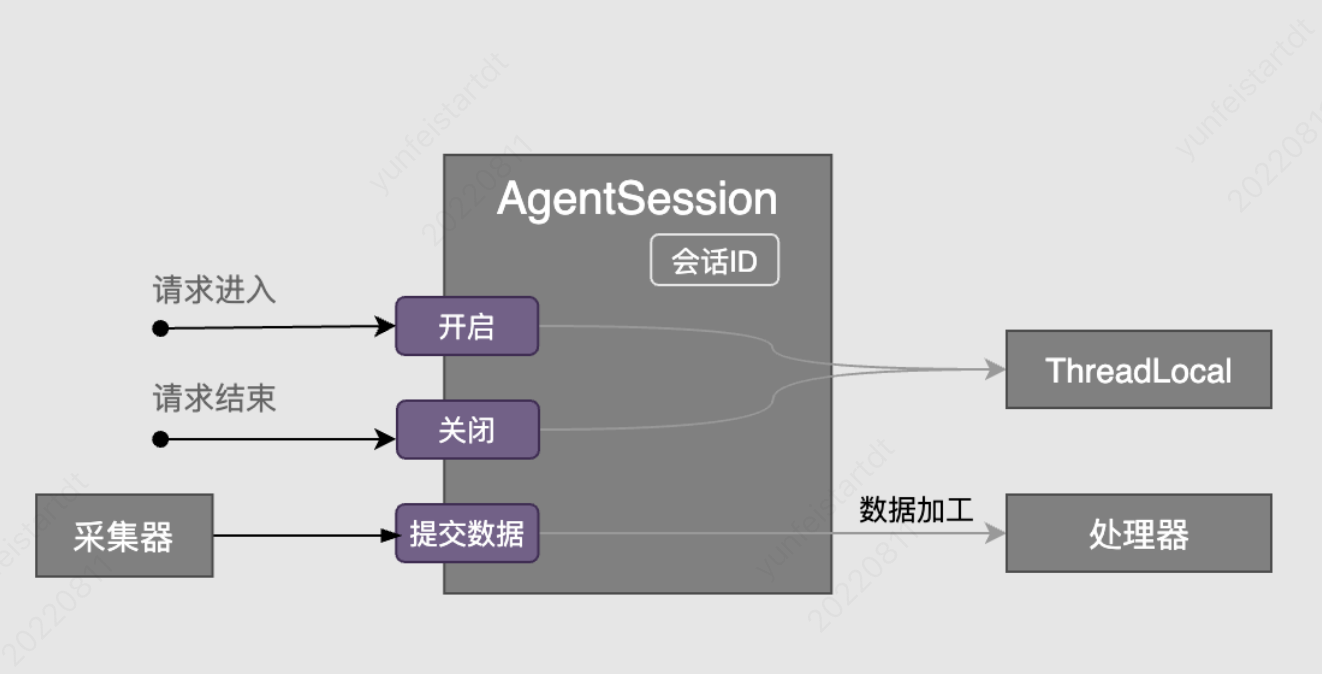
由于一次请求,执行顺序都是http-->service-->jdbc-->http响应,所以我们在**http采集的begin方法中打开会话,在http采集的end方法中关闭会话**。service和jdbc采集只需将采集到的数据在各自的end方法中进行推送,即调用不同的处理器处理采集数据即可。
#### 数据管道
数据采集完整功能包括:从业务代码中采集具体数据、根据采样率进行过滤、序列化成Json、 基于Http上传。这些需求可以抽象成两部分:采集与加工处理,我们把它设计了两个组件采集器 (Collector)、处理器(Processor)。某个数据采集包括一个采集器以及N个处理器,处理器通过 order进行排序,一起组成了一个数据管道。
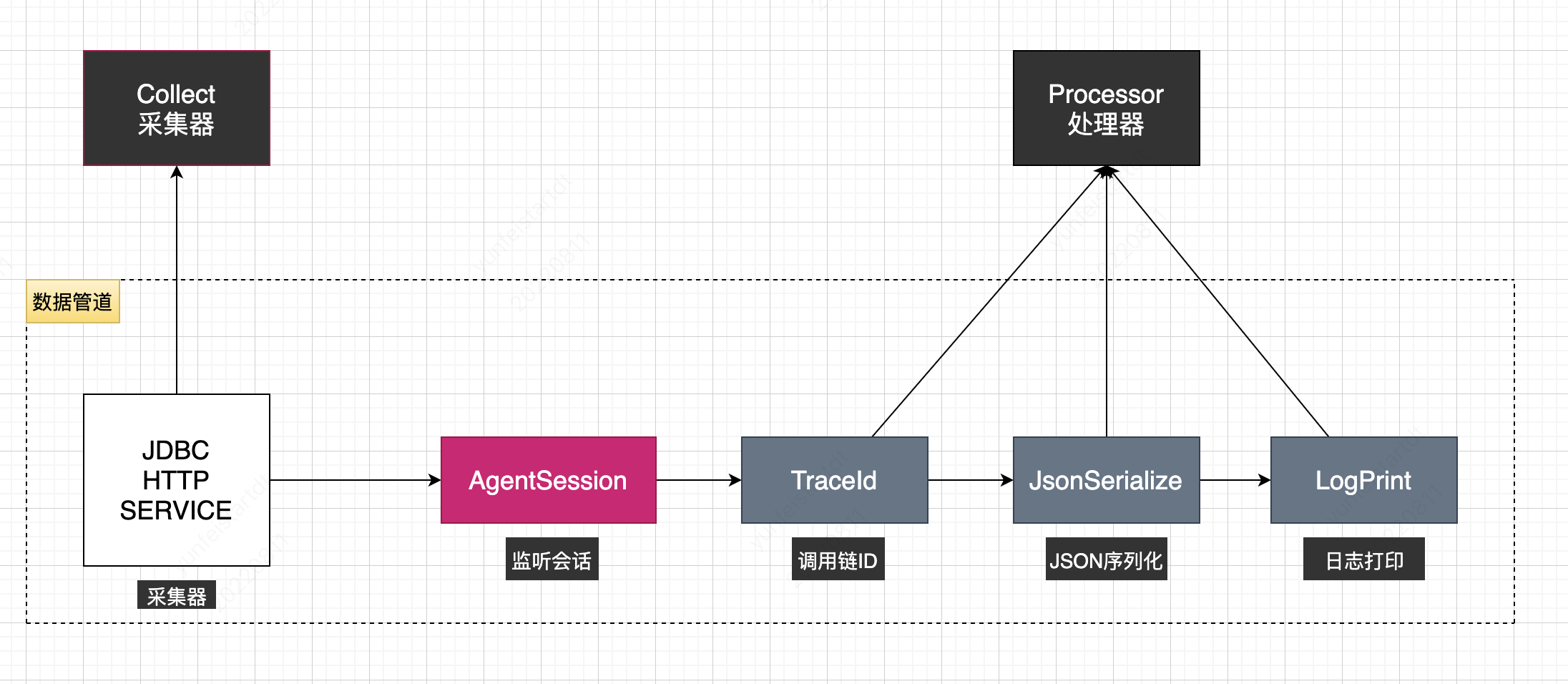
注:为了后续的兼容,上面的TraceId改为通用信息处理器,它不仅包含了tranceId获取,还包含了采集的类型,应用名称,host等信息:
~~~Java
public class BaseInfoProcessor implements Processor {
@Override
public Object accept(AgentSession agentSession,Object o) {
if(o instanceof BaseDataNode){
((BaseDataNode)o).setTraceId(agentSession.getSession());
((BaseDataNode)o).setAppName(Agent.config.getProperty("app.name","未定义"));
((BaseDataNode)o).setHost(NetUtils.getLocalHost());
((BaseDataNode)o).setModeType(o.getClass().getSimpleName());
}
return o;
}
}
~~~
#### 采集器
为了给采集器最大灵活性,这里只定义了一个注册接口,它在Agent加载的时候注册,传递 Instrumentation接口给采集器用于插桩。采集到的数据统一交给会话再进一步加工处理。
**ps:**这里需要注意一下service采集,因为service采集是采集我们的业务方法,但是业务方式是很庞大的,我们不能将需要插桩的方法写死,而是要灵活配置,所以我们可以在VM参数中定义`service.include`参数来指明要采集的目标,`service.exclude`参数来指明排除的目标,这里使用了一个jacoco框架中的工具类`WildcardMatcher`来解析参数中的值。
#### 处理器
这里处理器的生命周期是与监控会话相同的,每个会话中处理都有独立的实例,在会话开启时实 例化,并通过order 进行排序。采集到数据一次调用处理器的accept 方法,并在该方法中加工 改变数据,交给一下个处理器处理。如果返回Null表示处理完成,不在传递给下一个处理器。 最后处理器提供了一个finish 方法用于 会话结束时调用,以执行一些资源释放,或数据统计的 操作。
**ps:**日志处理这里需要注意,我们会调用`fileWriter`将数据写入日志,目前会写三种数据,即http数据、service数据、sql数据,所以没写完一种数据后,掉用`flush`方法先写入缓冲区,但是流必须要关闭,不然就会导致日志中会出现多条相同的日志,但是流又不能每次写完一种数据就关闭,这样就会导致流频繁关闭,造成文件不可写入。所以正确的做法应该是定义一个计数器表示采集器的数量,每次进行处理的时候减1,当为0的时候即没有数据要写了,这时候再关闭流:
~~~Java
/**
* 表示需要处理的收集器数量,当为0后所有数据都处理完毕,目的是为了关闭流
*/
public final AtomicInteger collectCount=new AtomicInteger(3);
public void push(Object node){
//每次推数据都-1
collectCount.decrementAndGet();
Objects.requireNonNull(node);
for (Processor processor : processorList) {
//顺序执行处理器逻辑
//当前参数经过处理后作为下一次处理的参数
node = processor.accept(this,node);
if(node==null){
break;
}
}
}
//日志处理器
@Override
public STATUS accept(AgentSession agentSession, String s) {
try {
logger.info("写入日志-----:"+s);
fileWriter.write( s +"\r\n");
//刷新缓冲区,此时数据还没有写入文件,只写到缓冲区,后面还可以继续写
fileWriter.flush();
} catch (IOException e) {
logger.error("日志写入失败",e);
}finally {
//当所有数据都收集完后(即http、service、sql),再关闭
//不然每次收集完一次(比如http)就关闭,会造成流频繁关闭,导致后面无法写
if(agentSession.collectCount.get()==0) {
try {
//一定要关闭,通知系统后面不能再写数据了,即当前一次会话结束,保证只会打印当次会话日志
fileWriter.close();
} catch (IOException e) {
logger.error("文件关闭失败", e);
}
}
}
return STATUS.OVER;
}
~~~
#### 配置文件
我们可以自定义配置文件的优先级,比如基于JVM参数的优先级大于agent的配置文件
~~~Java
public static Properties config;
public static void premain(String args, Instrumentation instrumentation){
config = new Properties();
// 装截agent 配置文件
config.putAll(getAgentConfigs());
// 基于JVM参数配置,优先级高
if (args != null && !args.trim().equals("")) {
try {
//多个参数以逗号分隔
config.load(new ByteArrayInputStream(
args.replaceAll(",", "\n").getBytes()));
} catch (IOException e) {
throw new RuntimeException(String.format("agent参数无法解析:%s", args), e);
}
}
...
}
// 读取agent 配置
private static Properties getAgentConfigs() {
// 读取agnet 配置,这里得到的就是target目录
URL u = Agent.class.getProtectionDomain().getCodeSource().getLocation();
File file = new File(new File(u.getFile()).getParentFile(), "conf/config.properties");
if (!file.exists() || file.isDirectory()) {
logger.warn("找不到配置文件:" + file.getPath());
return new Properties();
}
Properties properties = new Properties();
try {
properties.load(new FileInputStream(file));
} catch (IOException e) {
throw new RuntimeException(e);
}
return properties;
}
~~~
#### 效果
请求接口两次,由于我们采集了http信息和sql信息,所以会在日志中打印相关的日志:
~~~
八月 16, 2022 4:36:13 下午 com.cxylk.agent2.process.LogPrintProcessor accept
信息: {"jdbcUrl":"jdbc:mysql://172.16.211.139:4000/nuza_system?autoReconnect=true&useUnicode=true&characterEncoding=utf8&zeroDateTimeBehavior=convertToNull&useSSL=false&serverTimezone=Asia/Shanghai&rewriteBatchedStatements=true","sql":"select * from merchant_user where user_name=?","databaseName":"nuza_system","params":[{"index":1,"value":"lktest"}],"traceId":"c6321a3b31564ab689ec4f53c6ab1bdd","beginTime":{"date":{"year":2022,"month":8,"day":16},"time":{"hour":16,"minute":35,"second":46,"nano":238000000}},"useTime":54}
八月 16, 2022 4:42:20 下午 com.cxylk.agent2.process.LogPrintProcessor accept
信息: {"url":"http://127.0.0.1:8080/user/find","clientIp":"127.0.0.1","traceId":"c6321a3b31564ab689ec4f53c6ab1bdd","beginTime":{"date":{"year":2022,"month":8,"day":16},"time":{"hour":16,"minute":35,"second":45,"nano":762000000}},"useTime":370182}
八月 16, 2022 4:42:52 下午 com.cxylk.agent2.process.LogPrintProcessor accept
信息: {"jdbcUrl":"jdbc:mysql://172.16.211.139:4000/nuza_system?autoReconnect=true&useUnicode=true&characterEncoding=utf8&zeroDateTimeBehavior=convertToNull&useSSL=false&serverTimezone=Asia/Shanghai&rewriteBatchedStatements=true","sql":"select * from merchant_user where user_name=?","databaseName":"nuza_system","params":[{"index":1,"value":"lktest"}],"traceId":"3f0353f1866a4b75adea847449b929d0","beginTime":{"date":{"year":2022,"month":8,"day":16},"time":{"hour":16,"minute":42,"second":52,"nano":593000000}},"useTime":30}
八月 16, 2022 4:42:52 下午 com.cxylk.agent2.process.LogPrintProcessor accept
信息: {"url":"http://127.0.0.1:8080/user/find","clientIp":"127.0.0.1","traceId":"3f0353f1866a4b75adea847449b929d0","beginTime":{"date":{"year":2022,"month":8,"day":16},"time":{"hour":16,"minute":42,"second":52,"nano":555000000}},"useTime":87}
~~~
可以看到,第一次请求的traceId=c6321a3b31564ab689ec4f53c6ab1bdd,第二次请求的traceId=3f0353f1866a4b75adea847449b929d0
当然,如果想让日志直接打印在控制台,可以在日志处理器中使用jdk原生的日志框架:
~~~java
Logger logger = Logger.getLogger(LogPrintProcessor.class.getName());
~~~
如果想收集service信息,并且指定收集的范围,可以这样:
~~~java
-javaagent:/Users/likui/Workspace/github/treasure-map/agent2/target/agent2-0.0.1-SNAPSHOT.jar=service.include=com.cxylk.service.*
~~~
如果想指定日志文件生成的目录,可以在后面加参数log:
~~~java
-javaagent:/Users/likui/Workspace/github/treasure-map/agent2/target/agent2-0.0.1-SNAPSHOT.jar=service.include=com.cxylk.service.*,log=xxx
~~~
## 7、如何打造APM
经过上面的整体设计后,我们可以直接将改项目打造成APM项目。这里采用filebeat收集日志,然后将日志存储到es,再通过kibana展示。由于现在使用的机器是mac m1,基于arm架构,所以这里采用的框架版本都为7.16.2。
所以我们需要再新建一个日志目录(区别于前面的logger日志),这个日志就是filebeat采集的来源,然后配置filebeat.yml文件:
~~~yml
filebeat.inputs:
- type: log
enabled: true
paths:
- /Users/likui/Workspace/github/treasure-map/logs/*.log
document_type: "test-log"
fields:
agent_version: "1.0"
fields_under_root: true
tags: ["apm"]
# 开启json解析,不然所有字段都会放在message字段中
json.keys_under_root: true
json.overwrite_keys: true
# 如果是换行展示,需要匹配换行,开启了json解析后,就不能再开启下面的配置
# multiline.pattern: '^\n'
# multiline.negate: true
# multiline.match: after
# ---------------------------- Elasticsearch Output ----------------------------
output.elasticsearch:
hosts: ["localhost:9200"]
# 按天创建索引
index: "apm-%{+YYYY.MM.dd}"
enable: true
# 关闭默认的模板配置
setup.template.enabled: false
# 使用该JSON文件来指定字段的模板,不然会使用es默认的模板
setup.template.path: "/Users/likui/Workspace/github/treasure-map/apm.json"
setup.template.name: "apm"
setup.template.pattern: "apm-*"
# 开启新设置的模板
setup.template.overwrite: true
setup.ilm.enabled: false
~~~
这里有个点需要注意下,当后面使用spring-data-es读取es数据时,因为filebeat采集的日志没有过滤host、agent等信息,就存储到了es,然后就会导致字段映射报错,所以我们需要在配置文件中过滤这些字段:
~~~ xml
processors:
- drop_fields:
fields: ["log","input","host","agent","ecs"]
~~~
es+kibana通过docker-compose启动即可,配置如下:
~~~yml
version: '3.3'
services:
elasticsearch:
image: elasticsearch:7.16.2
container_name: elasticsearch
ports:
- "9200:9200"
- "9300:9300"
environment:
- "discovery.type=single-node"
volumes:
- /Users/likui/Workspace/docker/volume/elasticsearch/data:/usr/share/elasticsearch/data #数据文件挂载
- /Users/likui/Workspace/docker/volume/elasticsearch/plugins"/usr/share/elasticsearch/piugins #插件文件挂载
kibana:
image: kibana:7.16.2
container_name: kibana
environment:
- "ELASTICSEARCH_HOSTS=http://elasticsearch:9200/"
ports:
- "5601:5601"
links:
- elasticsearch
~~~
然后在kibana中创建索引即可展示日志信息(先通过接口采集一些信息)。
## 8、RPC调用链追踪
### 分布式调用链底层逻辑
关于分布式链路:
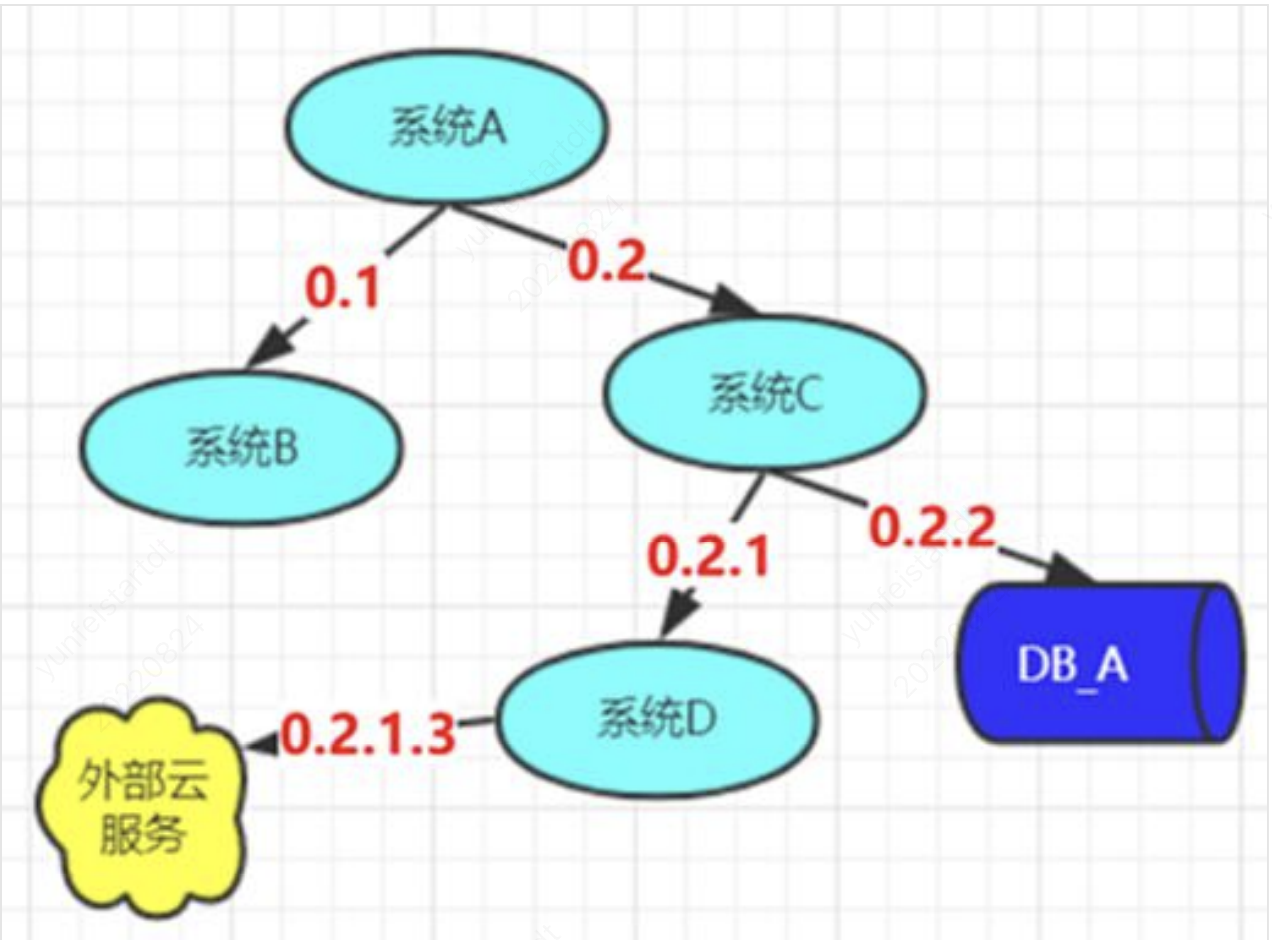
#### 调用链基本元素
1、事件:请求处理过程当中的具体动作
2、节点:请求所经过的系统节点,即事件的空间属性
3、时间:事件的开始和结束时间
4、关系:事件与上一个事件关系
调用链系统本质上就是用来回答这几个问题:
1、什么时间
2、在什么节点上
3、发生了什么事情
4、这个事情由谁发起
#### 事件捕捉
1、硬编码埋点捕捉
2、AOP埋点捕捉
3、公开组件埋点捕捉
4、字节码插桩捕捉
#### 事件串联
目的:
1、所有事件都关联到同一个调用
2、各个事件之间的层级关系
为了达到这两个目的,几乎所有的调用链系统都会有以下两个属性:
traceId:在整个系统中唯一,该值相同的事件表示同一次调用
spanId:在一次事件中唯一、并展示出事件的层级关系
问题:
1、怎么生成traceId
2、怎么传递参数
3、怎么在并发情况下不影响传递的结果
#### 串联的过程
1、由跟踪的起点生成一个traceId,一直传递至所有节点,并保存在事件属性值当中。
2、由跟踪的起点生成初始spanId,没捕捉一个事件ID加1,没传递一次,层级加1
#### spanId自增生成方式
如何在多线程环境下保证自增的正确性?
解决方法是每个跟踪请求创建一个互相独立的会话,spanId的自增都基于该会话实现。会话对象的存储基于threadLocal实现。
#### span基本内容
在调用链中一个span即代表一个时间跨度下的行为动作,它可以是在一个系统内的时间跨度,也可能是跨多个服务系统的。通常情况下一个span组成包括
1、名称:即操作的名称
2、spanId:当前调用中唯一ID
3、parentId:表示其父span
4、开始与结束时间
#### 端到端span
一次远程调用需要记录几个Span呢?我们需要在客户端和服务端分别记录Span信息,这样才能 计在两个端的视角分别记录信息。比如计算中间的网络IO。
在Dapper 中分布式请求起码包含如下四个核心埋点阶段:
1. 客户端发送 cs(Client Send):客户端发起请求时埋点,记录客户端发起请求的时间戳
2. 服务端接收 sr(Server Receive):服务端接受请求时埋点,记录服务端接收到请求的时间 戳
3. 服务端响应 ss(Server Send):服务端返回请求时埋点,记录服务端响应请求的时间戳
4. 客户端接收 cr(Client Receive):客户端接受返回结果时埋点,记录客户端接收到响应时 的时间戳
通过这四个埋点信息,我们可以得到如下信息: 客户端请求服务端的网络耗时:sr-cs 服务端处理请求的耗时:ss-sr 服务端发送响应给客户端的网络耗时:cr-ss 本次请求在这两个服务之间的总耗时:cr-cs。、
以上这些埋点在 Dapper 中有个专业的术语,叫做 Annotation。
我们可以通过下面这张图比较清楚的展示了整个过程:
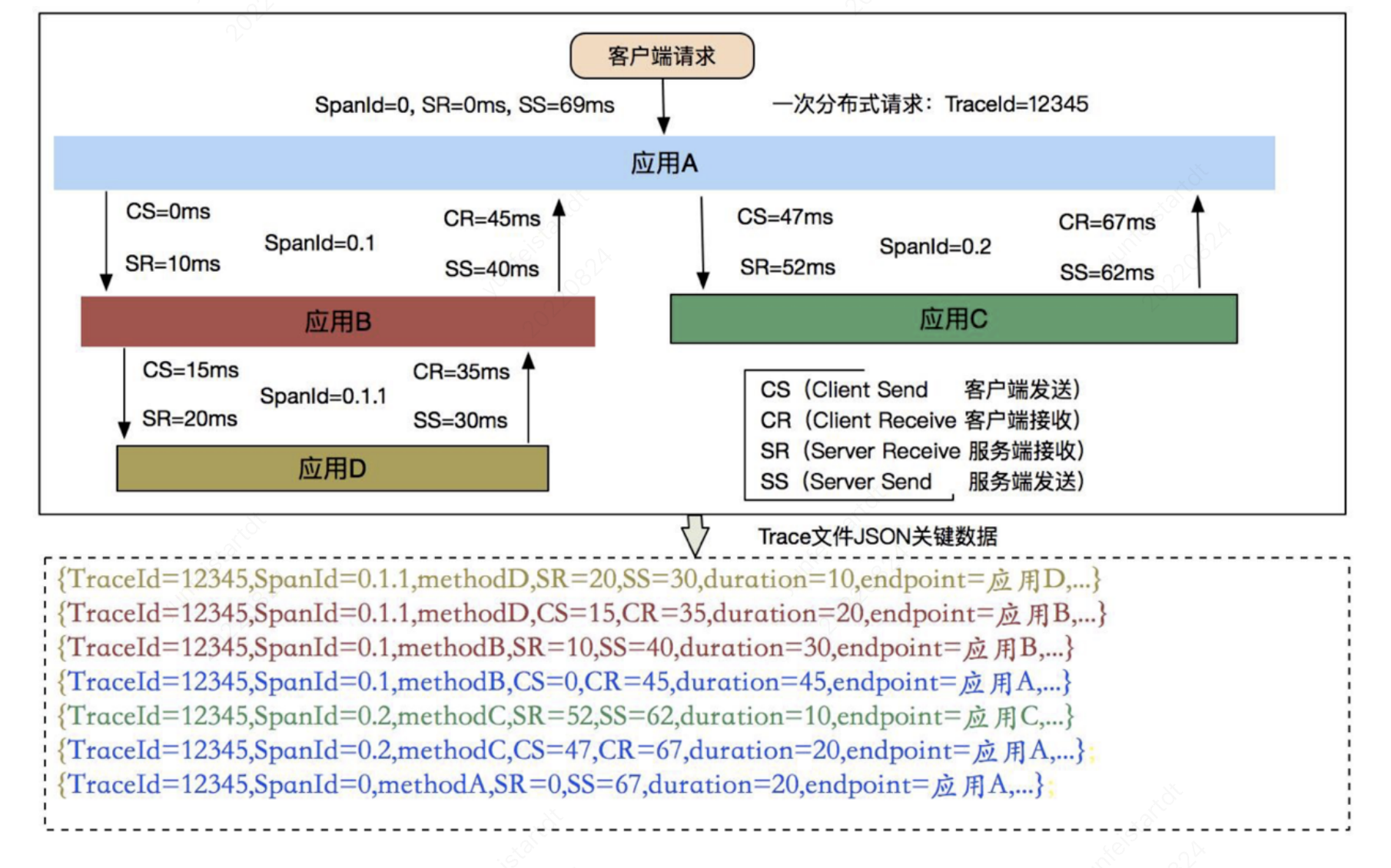
### Dubbo调用链追踪实现
这里我们选择RPC中的dubbo进行具体的实现。
#### 链路会话传递
我们先来看下整个链路会话的一个传递:
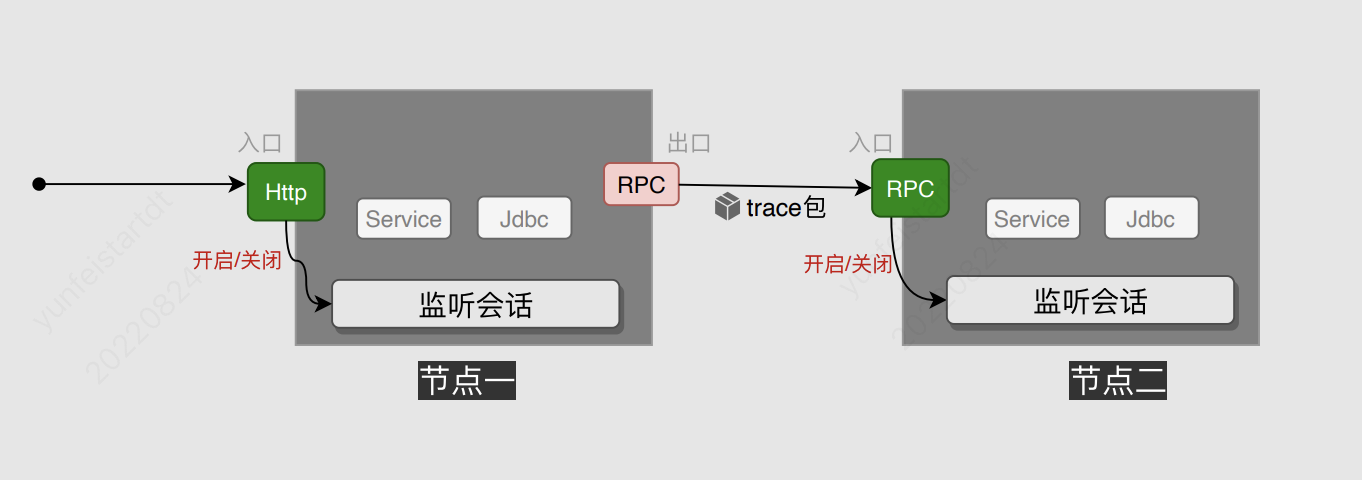
关于入口节点:
1、入口通常也是出口,其职责是在请求进入时开启当前请求的会话,出去时关闭当前请求的监听会话
2、解析请求中附带的trace包,并在它基础上开启监听会话
3、开启的会话,必须确保其能按时关闭
关于出口节点:
1、指当前应用调用外部系统,需要在不影响业务的情况下将当前链路会话传递到下游节点
#### 会话设计
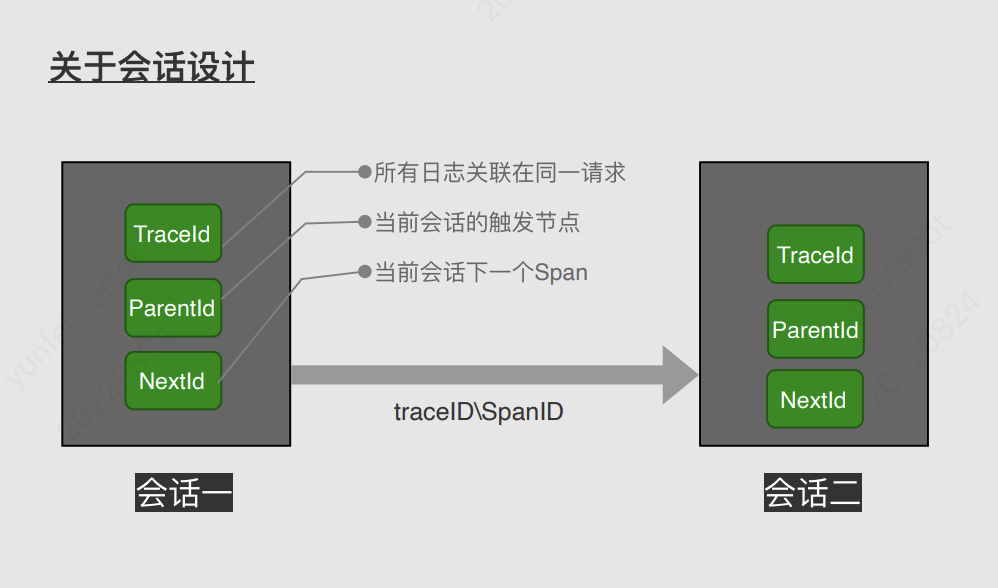
#### 具体实现
首先是插桩点。因为Dubbo有调用过程和响应过程,所以应该有两个插桩点。
这里需要注意的是,为了解决classLoader的问题,依然采用适配器的方式。代码见agent2项目下dubbo目录。
##### dubbo调用过程
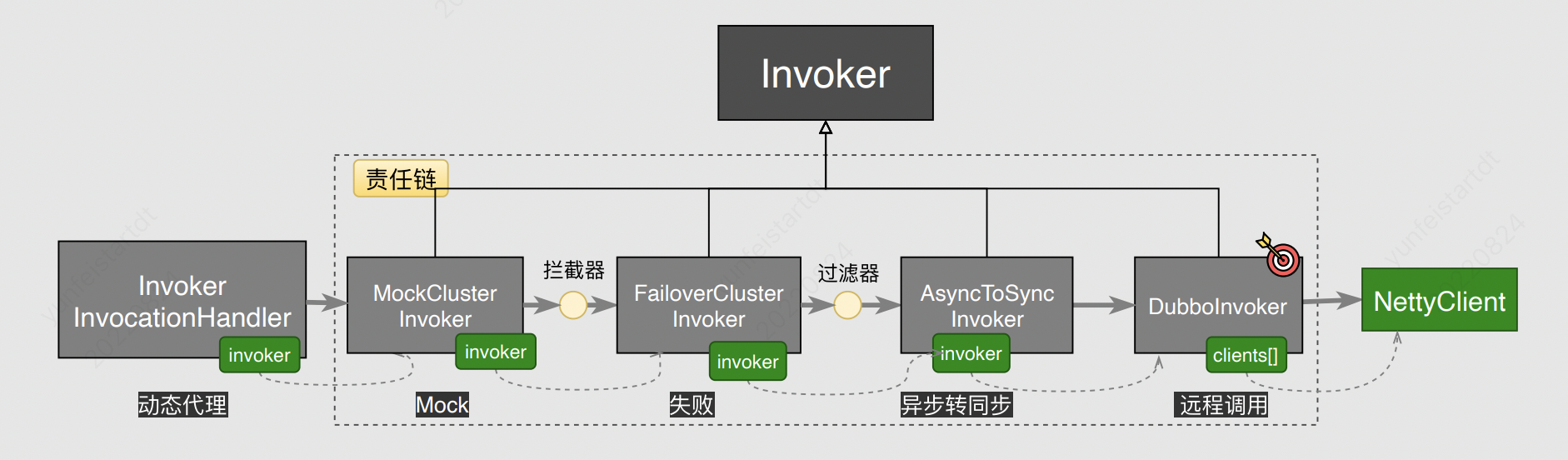
可以看到,经过责任链的处理,最终会通过`DubboInvoker`发起调用,所以我们插桩点就是它。
**过程:**
1、拦截`DubboInvoker`的`doInvoker`方法
2、隐式传参traceId以及当前spanId到下游节点(也就是服务端)
3、采集当前RPC调用信息(接口、服务端URL、方法、时间等,通过`Invocation`和`Invoker`)并保存至AgentSession
这里提一下dubbo的隐私传参:当我们有**将额外的参数传递给下游服务**的需求时,我们不可能修改方法的参数签名,这与业务耦合了,此时就需要用到dubbo的隐私参数`attachment`了,可以把它理解为dubbo协议中的一个扩展点。类似于http协议,我们可以自定义请求头信息。而在dubbo中,我们也可以自定义RPC请求中的参数。
##### dubbo响应过程
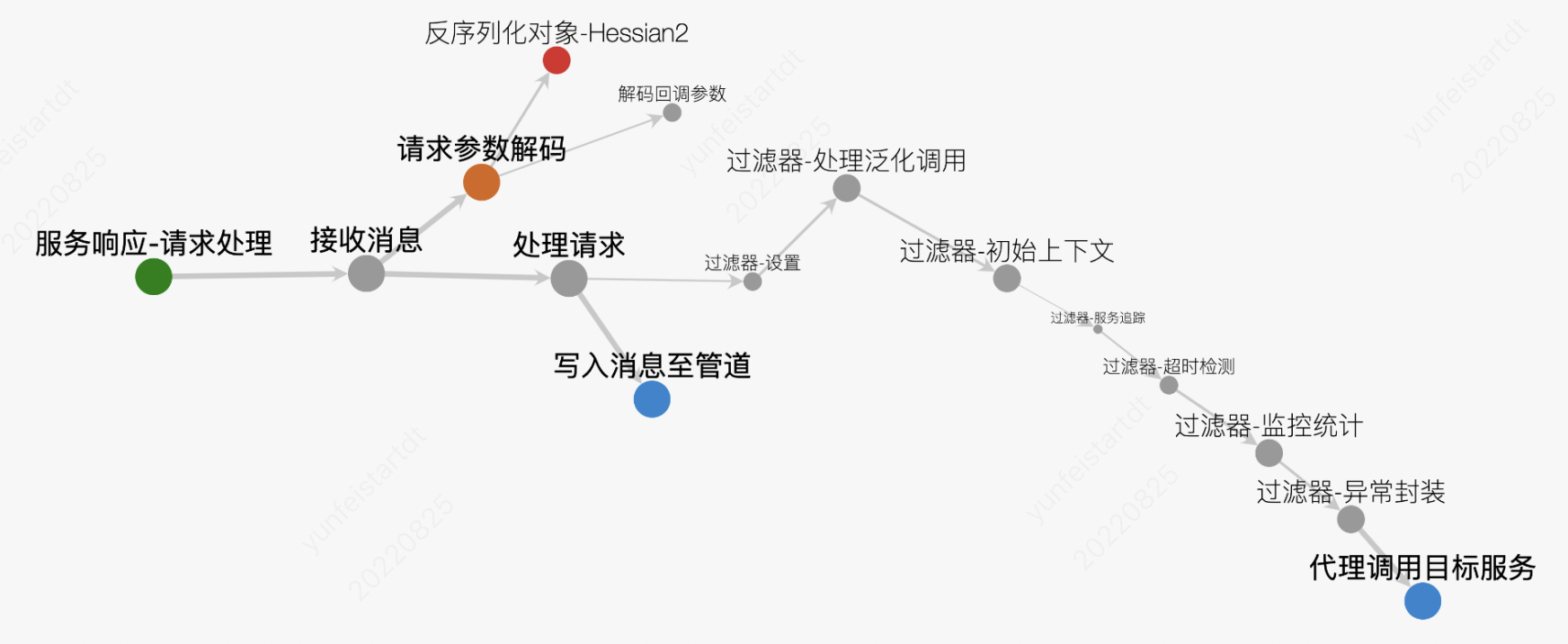
插桩点为`GenericFilter`。
**过程:**
1、拦截`invoke`方法
2、解析上游传递的隐私参数traceId以及parentId,请基于它重新开启一个会话(因为这属于另外一个节点了)
3、采集当前调用信息(通过`Invoker`和`Invocation`)
4、请求结束后关闭会话
我们可以看一下采集到的日志:
~~~json
# 客户端dubbo信息
{"remoteUrl":"dubbo://10.10.10.237:20880/com.cxylk.service.DubboUserService?anyhost=true&application=dubbo-client&check=false&deprecated=false&dubbo=2.0.2&dynamic=true&generic=false&init=false&interface=com.cxylk.service.DubboUserService&metadata-type=remote&methods=getUserByName&pid=63647&qos.enable=false®ister.ip=10.10.10.237&release=2.7.8&remote.application=dubbo-server&side=consumer&sticky=false&timeout=3000×tamp=1661325410828","serviceInterface":"com.cxylk.service.DubboUserService","serviceMethodName":"getUserByName","seat":"client","traceId":"382276bca75f4a4ca4632eee595c5067","spanId":"0.1","beginTime":{"date":{"year":2022,"month":8,"day":24},"time":{"hour":15,"minute":18,"second":11,"nano":773000000}},"useTime":22,"appName":"未定义","host":"10.37.129.2","modeType":"DubboInfo"}
# 服务端jdbc信息
{"jdbcUrl":"jdbc:mysql://172.16.211.139:4000/nuza_system?autoReconnect=true&useUnicode=true&characterEncoding=utf8&zeroDateTimeBehavior=convertToNull&useSSL=false&serverTimezone=Asia/Shanghai&rewriteBatchedStatements=true","sql":"select * from merchant_user where user_name=?","databaseName":"nuza_system","params":[],"traceId":"382276bca75f4a4ca4632eee595c5067","spanId":"0.1.1","beginTime":{"date":{"year":2022,"month":8,"day":24},"time":{"hour":15,"minute":18,"second":12,"nano":383000000}},"useTime":60,"appName":"未定义","host":"10.37.129.2","modeType":"SqlInfo"}
# 服务端dubbo信息
{"serviceInterface":"com.cxylk.service.DubboUserService","serviceMethodName":"getUserByName","seat":"server","traceId":"382276bca75f4a4ca4632eee595c5067","spanId":"0.1","beginTime":{"date":{"year":2022,"month":8,"day":24},"time":{"hour":15,"minute":18,"second":12,"nano":1000000}},"useTime":481,"appName":"未定义","host":"10.37.129.2","modeType":"DubboInfo"}
# 客户端http信息
{"url":"http://127.0.0.1:8080/user/find2","clientIp":"127.0.0.1","traceId":"382276bca75f4a4ca4632eee595c5067","spanId":"0","beginTime":{"date":{"year":2022,"month":8,"day":24},"time":{"hour":15,"minute":18,"second":11,"nano":723000000}},"useTime":877,"appName":"未定义","host":"10.37.129.2","modeType":"HttpInfo"}
~~~
可以看到,traceId是全局唯一的,它代表了当前的一次调用。
客户端http信息中,spanId是0,因为我们的入口就是http调用(这里开启了会话,parentId就是spanId),然后在客户端中通过dubbo发起了远程调用,这里客户端产生了一次dubbo事件,所以spanId加1,变成了0.1,然后通过隐式传参将客户端的spanId作为parentId传递给了服务端,所以服务端的dubbo信息中的spanId也是0.1,为什么他们的spanId相同呢?因为这是一次调用中产生的dubbo事件,不管是客户端发起的dubbo调用还是服务端的dubbo响应,他们都是dubbo事件。**并且dubbo事件作为服务端的起始事件,需要重新开启会话,设置traceId和parentId,parentId就是dubbo事件的spanId**。
最后在服务端访问了数据库,产生了sql事件,它的parentId就是dubbo信息的spanId,所以它的spanId是0.1.1。
所以我们可以得出结论:**谁是当前节点最开始产生的事件,那么它的spanId就会作为当前节点的parentId,后续该节点产生的事件的parentId都是它**。
## 9、动态代码覆盖率追踪
### 代码覆盖率
所谓的代码覆盖率,指的就是**追踪测试⽤例对应执⾏过的代码,覆盖越全,表示测试越精准**。常用的覆盖率工具有jacoco,idea。我们以jacoco为例,来了解代码覆盖的实现原理:
jacoco也是通过agent探针的方式,将agent插入到目标应用:

然后对代码进行修改,我们看下修改前和修改后的逻辑:

没错,jacoco的原理就是在每条指令码前将数组位设置为true。具体实现在`ProbeInserter`这个类。
### 动态代码覆盖
我们发现,上面这种方式只能是一个静态追踪的,如果想要覆盖指定时间段内,指定线程所执行过的方法(栈帧),那么我们就得进行改造。而方法的内存模型又与线程栈有关。
#### JVM线程栈模型
我们知道,在Java中,没一个线程都有自己的虚拟机方法栈,用于描述方法执行的内存模型,每一个方法从调用到执行完成的过程,就对应者一个栈帧(方法执行时创建)在虚拟机栈中入栈到出栈的过程:

而栈帧里面还有局部变量表和操作数栈等。
我们要做的就是将上面的模型抽象成数据结构,学过数据结构的话我们都知道,栈有两种实现方式,一种是数组,一种是链表,这里我们采用类似链表的实现方式。
#### 采集模型
##### stackNode
stackNode表示一个方法的执行栈帧,它有如下属性:
~~~Java
/**
* 节点id,最后一个小数点前面的表示父节点id,小数点后面的表示子节点数量
*/
private String id;
/**
* 类ID,ASM会自动生成
*/
private Long classId;
/**
* 类名
*/
private String className;
/**
* 方法名
*/
private String methodName;
/**
* 行号
*/
private final List lines=new ArrayList<>();
/**
* 栈帧数量
* 如果一个方法没有被多次调用,size始终为1
* 否则它等于一个方法被重复调用了多次
*/
protected int size;
/**
* 方法是否调用完成
*/
private boolean done;
/**
* 耗时,因为执行速度很快,所以这里用纳秒表示
*/
private Long useTime=0L;
//以下字段在序列化时忽略
/**
* 开始时间
*/
private transient Long beginTime;
/**
* 指向调用方
*/
private transient StackNode parent;
/**
* 指向被调用方,并且调用方可能有多个
*/
private transient final List childs=new ArrayList<>(20);
/**
* 当前node所属会话
*/
private transient StackSession stackSession;
~~~
##### stackSession
stackSession代表采集整个会话,构建该对象即表示会话开启。期间执行任一方法都要调用$begin和$end方法,并创建stackNode记录方法的执行数据,**会话期间始终有一个hotNode用于连接StackNode的父子关系**。它有如下属性和主要方法:
~~~Java
public class StackSession {
static final ThreadLocal sessions =new ThreadLocal<>();
/**
* 当前整个会话的根节点
*/
private StackNode rootNode;
/**
* 最重要的一个属性,它指向的是栈帧中的栈顶元素,
* 会话期间用于连接StackNode的父子关系
*/
private StackNode hotNode;
/**
* 调用的次数
*/
private int invokeCount=0;
/**
* 一个session期间执行的栈帧数量
* 用来限制方法调用深度
*/
private int nodeSize=0;
private int errorSize=0;
/**
* 虚拟机方法栈最大的容量
*/
static final int MAX_SIZE = 5000;
/**
* 构造该对象即表示开启会话
* 一个线程只能开启一次
*/
public StackSession(String originClass,String originMethod) {
if(sessions.get()!=null){
throw new RuntimeException("open code stack session fail,because current session already exists!");
}
//开启会话即构建一个根节点
StackNode rootNode=new StackNode(-1L,originClass,originMethod);
//根节点从0开始
rootNode.setId("0");
//调用次数+1
invokeCount++;
//hotNode可以理解为头指针,指向头节点
hotNode=rootNode;
this.rootNode=rootNode;
rootNode.setBeginTime(System.nanoTime());
sessions.set(this);
}
/**
* 每个方法入口处都要调用
* @param classId
* @param className
* @param methodName
* @return 返回一个Object或StackNode
*/
public static Object $begin(long classId,String className,String methodName){
StackSession session = sessions.get();
if(session==null){
//注意这里不能返回null,因为begin方法的返回结果要作为end方法的入参
return new Object();
}
StackNode node = session.addNode(new StackNode(classId, className, methodName));
return node==null?new Object():node;
}
/**
* 在每一个return指令之前都要调用,因为会存在分支流程语句
* @param node
*/
public static void $end(Object node){
StackSession session = sessions.get();
if(session!=null&&node instanceof StackNode){
//结束调用返回上一级
session.doneNode((StackNode) node);
}
}
/**
* 关闭会话,谁开启的会话会关闭
*/
public void close(){
if(sessions.get()==this){
sessions.remove();
}else {
throw new RuntimeException("code stack session close fail,because this not current session");
}
}
/**
* 添加节点(栈帧)
* @param node
* @return
*/
public StackNode addNode(StackNode node){
//调用次数+1
invokeCount++;
//限制方法栈的大小
if(nodeSize>=MAX_SIZE){
return null;
}
//还需要考虑调用重复方法的情况
boolean exist=false;
for (StackNode child : hotNode.getChilds()) {
//类名和方法名相同即为同一个方法
if(node.getClassName().equals(child.getClassName())&&node.getMethodName().equals(child.getMethodName())){
node=child;
exist=true;
break;
}
}
//没有调用相同方法的情况
if(!exist){
nodeSize++;
//将当前节点加入hotNode子节点
hotNode.getChilds().add(node);
//设置节点id,因为进入这里表示方法没有重复,所以节点id是唯一的
node.setId(hotNode.getId()+"."+hotNode.getChilds().size());
node.size=1;
node.setStackSession(this);
}else {
//出现调用相同方法的情况,只需要将node.size+1,表示重复方法的调用次数
node.size++;
}
//当前节点的父节点设置为hotNode
node.setParent(hotNode);
//hotNode指向node,也就是指向栈顶
hotNode=node;
node.setBeginTime(System.nanoTime());
return node;
}
/**
* 表示一个栈帧执行完成
* @param node
*/
public void doneNode(StackNode node){
//1、设置节点状态
node.setDone(true);
//2、hotNode回退到父节点
hotNode=node.getParent();
//3、统计栈帧执行用时
//因为一个方法存在重复调用情况,所以这里还要加上上一个重复方法的用时
node.setUseTime(node.getUseTime()+(System.nanoTime()-node.getBeginTime()));
}
~~~
我们用下面代码来模拟以下这个过程:
~~~Java
public void A(String name){
B();
if(name.equals("lk")){
//end
return;
}
C();
//end
}
public void B(){
C();
}
public void C(){
System.out.println("hello");
}
@org.junit.Test
public void codeCoverageTest() throws InterruptedException {
StackSession session=new StackSession("com.cxylk.Test","codeCoverageTest");
new Test().A("dsd");
session.close();
session.printStack(System.out);
Thread.sleep(Integer.MAX_VALUE);
}
~~~
#### 执行流程
这个流程用文字不好描述,我们通过下面这张图来说明(构造函数省略):
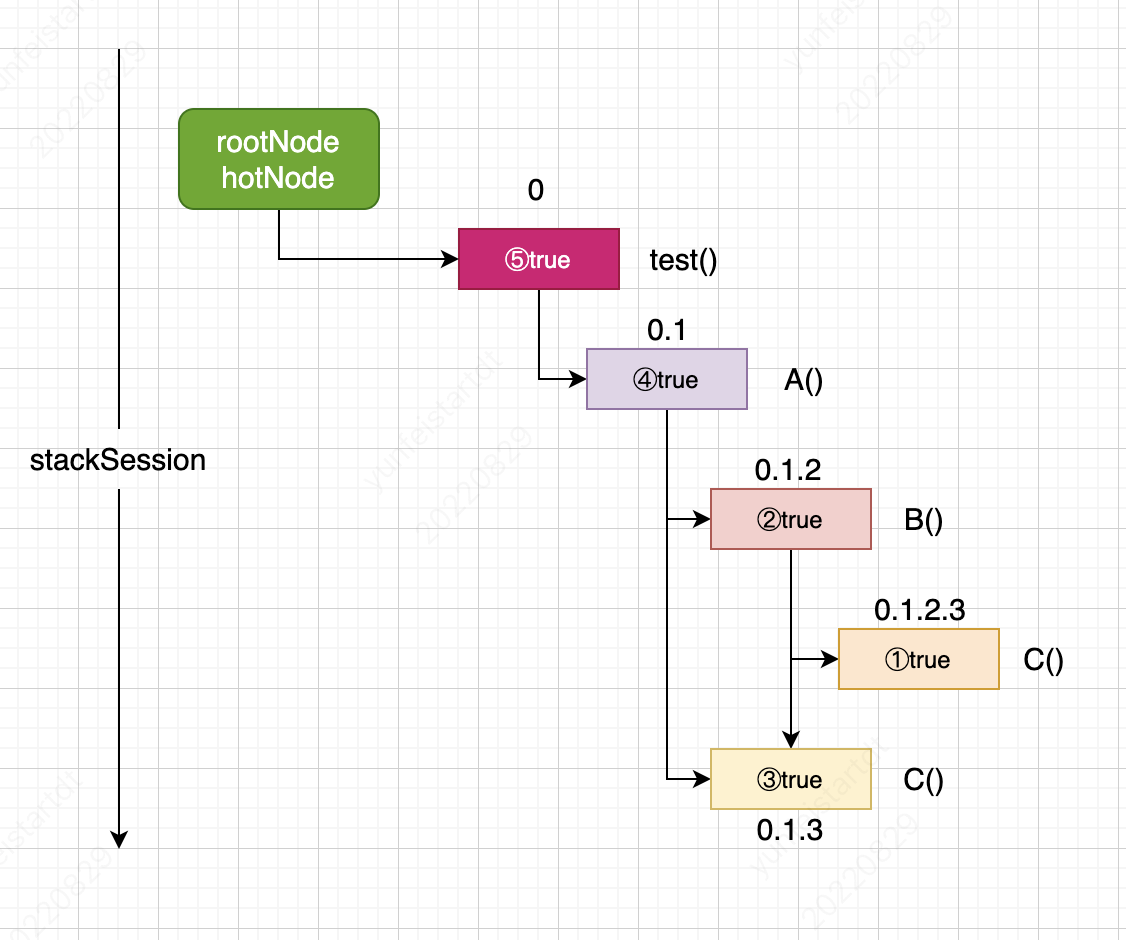
**rootNode始终指向根节点,而hotNode始终指向栈顶节点,hotNode是会变化的,这样正确理解这点,才能正确设置node.id的值**,上面的数字就是当前节点的id,id最后的一个数字就表示子节点的数量。当C()方法执行完后,hotNode回退到B()方法这个节点,然后B()方法执行完,hotNode回退到A()方法,此时hotNode有两个子节点B()和B()方法中的C()节点,而A()方法中还有一个C()方法,所以执行C()方法,此时将C()节点加入A()的子节点,所以C()的节点id为0.1.3。
#### 异常情况
最麻烦的事情就是方法执行中出现了异常,**这样的话end方法就执行不了,也就是说hotNode不会回退**。以上面这个流程为例,当我们在执行A()方法中的B()方法中的C()方法时,出现了异常,因为没有捕获,那么这个异常就会一直抛出到A()方法,如果A()进行了捕获处理了这个异常,我们接着执行A()中的C方法,但是**此时的hotNode指向的还是B()中的C()方法,导致的结果就是C()节点的父子关系错乱**。
如何解决?
我们的第一个反应就是将hotNode回退到A,这样C的父子关系就不会错乱,**但是hotNode不可能直接就回到A,它要先回到B,再回到A。而我们不知道哪行代码会出异常,也就是说,每执行一行代码,我们都要将hotNode设置为当前节点**。
所以说,没执行一行代码执行,我们都要插入这样的代码,怎么插入比较好呢?这里有个技巧,就是在hotNode中重写`equals`方法,这样不仅能拿到当前代码执行的行号,还能将hotNode设置为当前节点:
~~~Java
/**
* 1、记录行号
* 2、将hotNode置为当前节点
* @param obj
* @return
*/
@Override
public boolean equals(Object obj){
// 添加执行行号
if (obj instanceof Integer) {
if (!lines.contains(obj)) {
lines.add((Integer) obj);
}
//重置hotNode节点为当前节点
//为什么需要这么做?如果当一个方法还没执行end就出现了异常并且没有被捕获,它会一直向上抛出到根节点,
//那么hotNode就不会回退,当再次调用下个方法时,父子关系就会错乱
stackSession.setHotStack(this);
return false;
}
return super.equals(obj);
}
~~~
#### 编码实现
##### 插桩点
所以总结下来,我们的插桩点就应该有三个
**进入节点**:
1、创建StackNode,父节点指向hotNode
2、新建的node添加至hotNode的子节点集合
3、修改hotNode为新建的节点
**退出节点**:
1、将节点设置为完成状态
2、计算节点耗时
3、回退hotNode,将hotNode设置为当前节点的parent
*如果方法异常退出,无法回退,就得通过调用前来回退*
**调用前**:
1、记录行号
2、将hotNode置为当前节点
##### 实现
知道插桩点后,实现就简单了,我们只要在`jacoco`中的`ProbeInserter`类上修改即可。
1、方法入口处插入`$begin`方法:
~~~Java
@Override
public void visitCode() {
// 在方法开始处添加begin方法
// 将classId从常量池推送至栈顶
mv.visitLdcInsn(classInfo.getClassId());
// 将className从常量池推送至栈顶
mv.visitLdcInsn(classInfo.getClassName());
// 将methodName从常量池推送至栈顶
mv.visitLdcInsn(methodName);
// 调用begin方法
mv.visitMethodInsn(Opcodes.INVOKESTATIC, sessionClassName, "$begin",
"(JLjava/lang/String;Ljava/lang/String;)Ljava/lang/Object;", false);
mv.visitVarInsn(Opcodes.ASTORE, variable);
super.visitCode();
}
~~~
2、执行每行指令前都插入`equals`方法:
~~~Java
@Override
public void insertProbe(final int id) {
mv.visitVarInsn(Opcodes.ALOAD, variable);
InstrSupport.push(mv, currentLine);
//先将int转换为Integer,否则会报 Type integer (current frame, stack[1]) is not assignable to 'java/lang/Object'
mv.visitMethodInsn(Opcodes.INVOKESTATIC, "java/lang/Integer", "valueOf", "(I)Ljava/lang/Integer;", false);
mv.visitMethodInsn(Opcodes.INVOKEVIRTUAL, "java/lang/Object", "equals", "(Ljava/lang/Object;)Z", false);
mv.visitInsn(Opcodes.POP);
}
~~~
这个`insertProbe`对应的就是`MethodVisitor`中的`visitLabel`方法,jacoco中添加了一个`MethodProbesAdapter`适配器继承了`MethodVisitor`,然后重写了`visitorLabel`方法。
另外,当前代码执行的行号是通过下面这个方法得到的:
~~~Java
@Override
public void visitLineNumber(final int line, final Label start) {
this.currentLine = line;
super.visitLineNumber(line, start);
}
~~~
3、插入`$end`方法,不能在`visitorEnd`里面插入,而应该在每个`return`指令之前插入:
~~~Java
@Override
public void visitInsn(final int opcode) {
// ATHROW 属异常退出方法
//return指令之前
if ((opcode >= Opcodes.IRETURN && opcode <= Opcodes.RETURN)/* || opcode == Opcodes.ATHROW*/) {
//将begin方法返回的结果从局部变量表推送至栈顶
mv.visitVarInsn(Opcodes.ALOAD, variable);
//调用StackSession的end方法
mv.visitMethodInsn(Opcodes.INVOKESTATIC, sessionClassName, "$end", "(Ljava/lang/Object;)V", false);
}
super.visitInsn(opcode);
}
~~~
##### 问题
1、当前局部变量表的位置如何计算呢?我们来看构造方法:
~~~java
ProbeInserter(final int access, final String name, final String desc, final MethodVisitor mv, final ClassInfo classInfo) {
super(InstrSupport.ASM_API_VERSION, mv);
this.clinit = InstrSupport.CLINIT_NAME.equals(name);
this.methodName = name+" "+desc;
this.classInfo = classInfo;
//如果是静态方法,那么局部变量表的槽位从0开始,否则从1开始(0存放this)
int pos = (Opcodes.ACC_STATIC & access) == 0 ? 1 : 0;
//计算占用局部变量表的大小
for (final Type t : Type.getArgumentTypes(desc)) {
pos += t.getSize();
}
variable = pos;
}
~~~
可以看到,根据当前方法是静态方法还是实例方法以及参数类型计算出应该从局部变量表的哪个槽位开始操作。
2、当在一个变量后新插入一个变量,那么这个新插入的变量应该从局部变量表的哪个位置访问呢?
我们来看一个例子:
~~~Java
public void test(String name,int a){
int b;
//插入c
int c;
System.out.println(c);
}
~~~
没插入c之前,b应该保存在局部变量表的3号槽位,那我们插入c后,c就存储在了4号槽位,所以我们访问c的时候应该是3+1,而我们如果要访问name这个变量的话,它的槽位还是1,是不会变化的,所以在`ProbeInserter`中有这么一个方法:
~~~Java
private int map(final int var) {
//之前的变量位置不变
if (var < variable) {
return var;
} else {
//新插入的变量位置+1
return var + 1;
}
}
~~~
##### 效果
接下来我们就看看插桩后的代码长什么样子,代码入口处在`CodeStackCollect`,其中调用到插桩的是如下几行代码:
~~~java
ClassReader reader = new ClassReader("com.cxylk.coverage.Hello");
final ClassWriter writer = new ClassWriter(reader, 0);
ClassInfo info = new ClassInfo(reader);
final ClassVisitor visitor = new ClassProbesAdapter(new ClassInstrumenter(info, writer),
true);
reader.accept(visitor, ClassReader.EXPAND_FRAMES);
~~~
执行链路是这样的:
Reader-->Visitor-->Adapter-->Instrumenter-->writer。
所以真正的实现在`ClassInstrumenter`中,在它重写的`visitorMethod`中
~~~Java
@Override
public MethodProbesVisitor visitMethod(final int access, final String name, final String desc, final String signature,
final String[] exceptions) {
InstrSupport.assertNotInstrumented(name, className);
final MethodVisitor mv = cv.visitMethod(access, name, desc, signature, exceptions);
if (mv == null) {
return null;
}
final MethodVisitor frameEliminator = new DuplicateFrameEliminator(mv);
final ProbeInserter probeVariableInserter = new ProbeInserter(access, name, desc, frameEliminator, probeArrayStrategy);
return new MethodInstrumenter(probeVariableInserter, probeVariableInserter);
}
~~~
会调用`ProbeInserter`构造方法得到一个`ProbeInserter`,然后调用`MethodInstrumenter`构造方法,最后当执行`MethodVisitor`中的方法时,会交给`ProbeInserter`执行,完成插桩逻辑。
~~~Java
public MethodInstrumenter(final MethodVisitor mv,
final IProbeInserter probeInserter) {
//指定下一个执行者为ProbeInserter
super(mv);
this.probeInserter = probeInserter;
}
~~~
最后我们看下插桩完成后的代码,以上面那个测试代码为例:
~~~Java
public class Test {
public Test() {
Object object = StackSession.$begin(-8084460584871028501L, "com/cxylk/Test", " ()V");
object.equals(12);
StackSession.$end(object);
}
/*
* WARNING - void declaration
*/
public void A(String string) {
void name;
Object object = StackSession.$begin(-8084460584871028501L, "com/cxylk/Test", "A (Ljava/lang/String;)V");
/*14*/ this.B();
object.equals(14);
/*15*/ if (name.equals("lk")) {
/*17*/ object.equals(17);
StackSession.$end(object);
return;
}
/*19*/ this.C();
/*21*/ object.equals(21);
StackSession.$end(object);
}
public void B() {
Object object = StackSession.$begin(-8084460584871028501L, "com/cxylk/Test", "B ()V");
/*23*/ this.C();
/*24*/ object.equals(24);
StackSession.$end(object);
}
public void C() {
Object object = StackSession.$begin(-8084460584871028501L, "com/cxylk/Test", "C ()V");
/*27*/ System.out.println("hello");
/*28*/ object.equals(28);
StackSession.$end(object);
}
/*
* WARNING - void declaration
*/
@org.junit.Test
public void codeCoverageTest() throws InterruptedException {
void session;
Object object = StackSession.$begin(-8084460584871028501L, "com/cxylk/Test", "codeCoverageTest ()V");
StackSession stackSession = new StackSession("com.cxylk.Test", "codeCoverageTest");
object.equals(32);
new Test().A("dsd");
object.equals(33);
/*34*/ session.close();
object.equals(34);
/*35*/ session.printStack(System.out);
object.equals(35);
/*36*/ Thread.sleep(Integer.MAX_VALUE);
/*37*/ object.equals(37);
StackSession.$end(object);
}
/*
* WARNING - void declaration
*/
@org.junit.Test
public void codeSourceTest() {
void codeSource;
Object object = StackSession.$begin(-8084460584871028501L, "com/cxylk/Test", "codeSourceTest ()V");
/*41*/ CodeSource codeSource2 = Hello.class.getProtectionDomain().getCodeSource();
object.equals(41);
/*42*/ System.out.println(codeSource);
object.equals(42);
/*43*/ System.out.println(codeSource.getLocation());
/*44*/ object.equals(44);
StackSession.$end(object);
}
private static /* synthetic */ int $jacocoSize(int n) {
int[] nArray;
int[] nArray2 = nArray = new int[0];
return nArray[n];
}
}
~~~