"` |
| `--qa_inst` | Instruction for context-based QA. | "Directly answer the question based on the context passage, no explanation is needed. If the context does not contain any evidence, output 'I cannot answer based on the given context.'" |
| `--se_inst` | Instruction for context-based QA with SelfElicit highlighting. Must contain markers. | "Directly answer the question based on the context passage, no explanation is needed. Within the context, {MARKER_IMPSTART} and {MARKER_IMPEND} are used to mark the important evidence. Read carefully but still keep your answer short, do not output the markers. If the context does not contain any evidence, output 'I cannot answer based on the given context.'" |
| `--cot_inst` | Instruction for context-based QA with Chain-of-Thought (COT) prompting. | "Directly answer the question based on the context passage, no explanation is needed. If the context does not contain any evidence, output 'I cannot answer based on the given context.' Think step by step to provide the answer." |
| `--pe_inst` | Instruction for extracting evidence from the context (1st step of PromptElicit). | "Please find the supporting evidence sentences from the context for the question, then copy-paste the original text to output without any additional words. Template for output: '\n- [sentence1]\n- [sentence2] ...'" |
## 📈 Results and Examples
### Qualitative Examples

Examples of SelfElicit highlighting evidence and helping LM to get the correct answer.
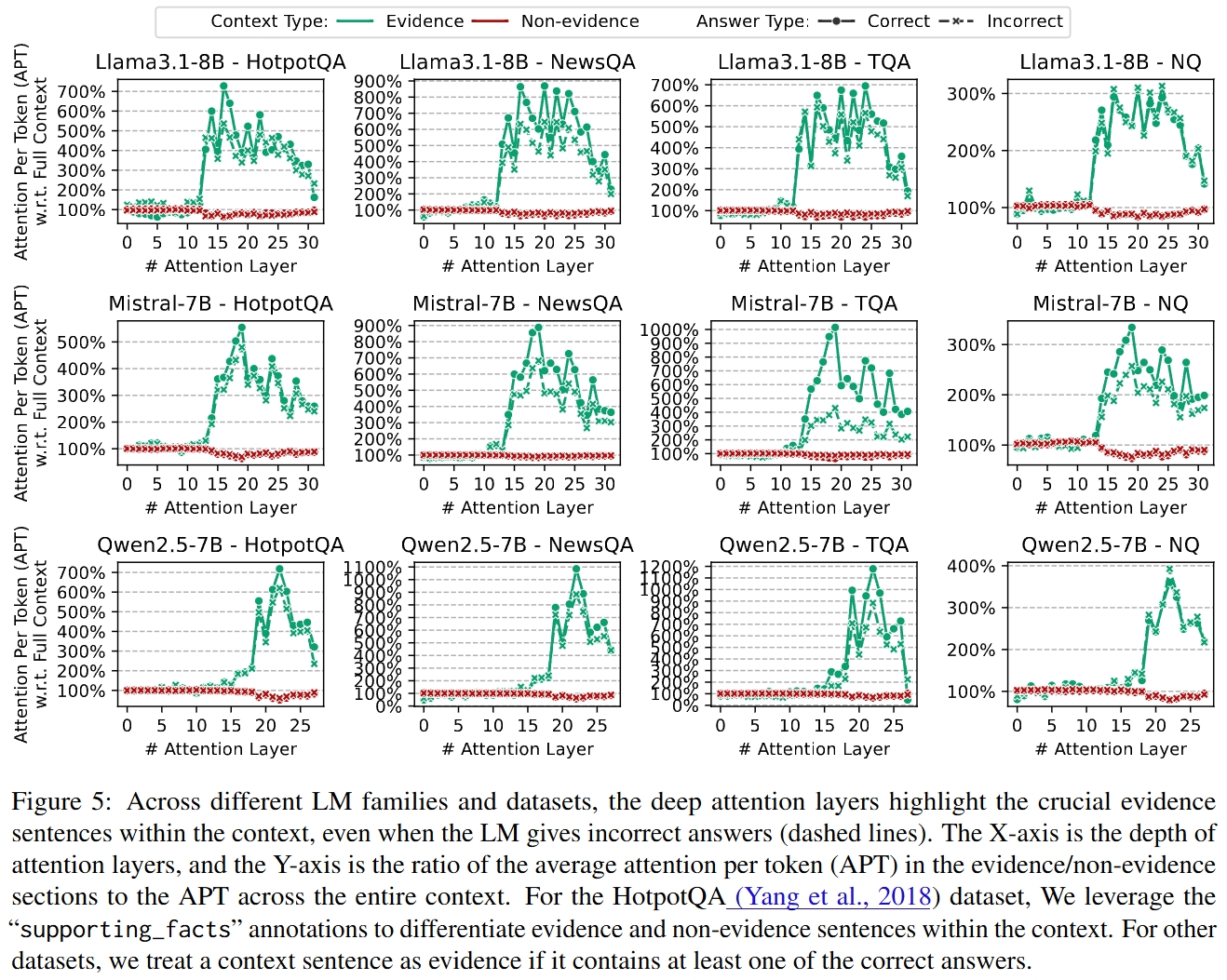
The "Evidence Reading Layers" pay high attention to the evidence sentences and exist across different LMs.
### Boosting QA Performance
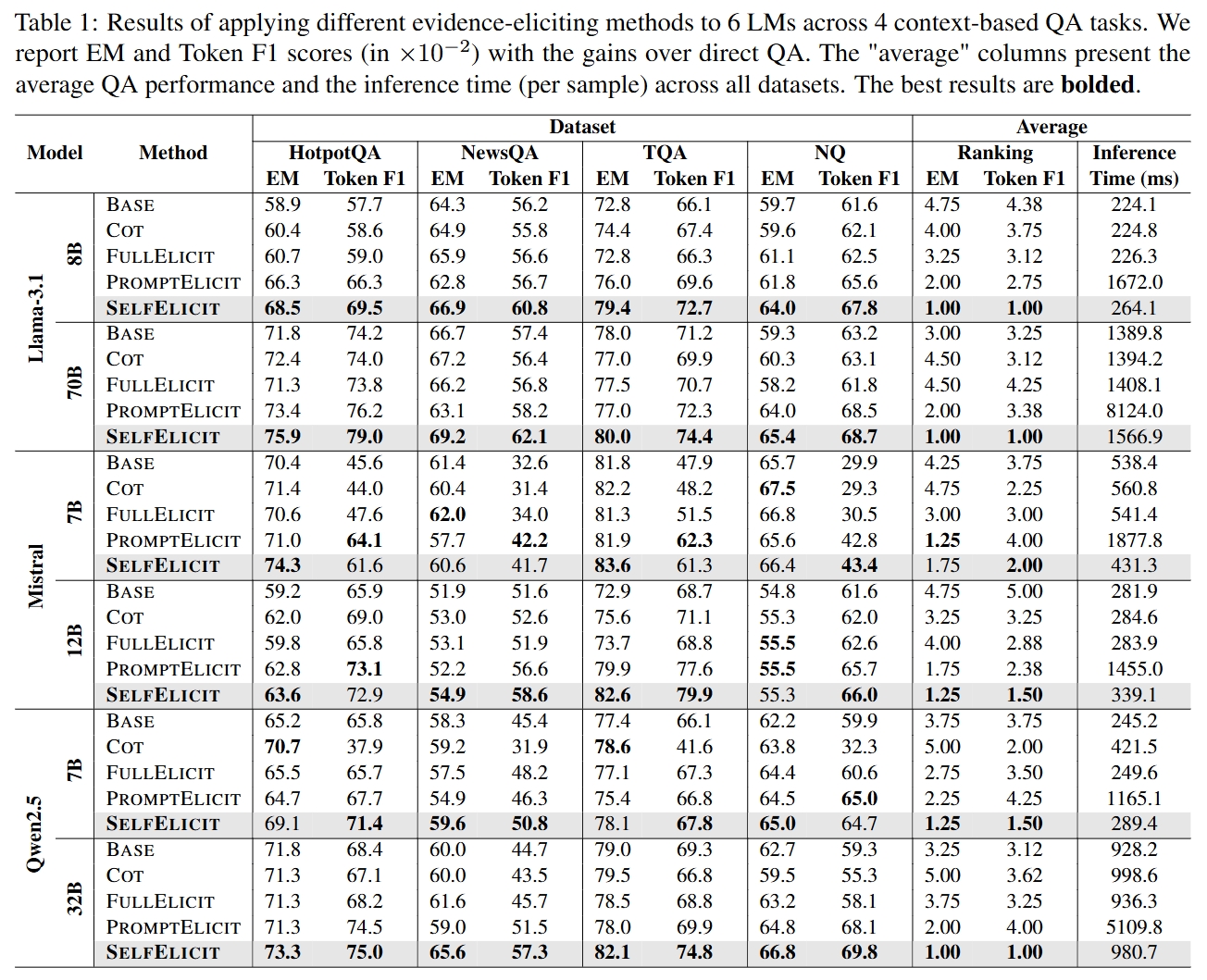
SelfElicit brings versatile performance boost on 4 context-based QA tasks with 6 different LMs.
### Efficient Inference-Time Augmentation
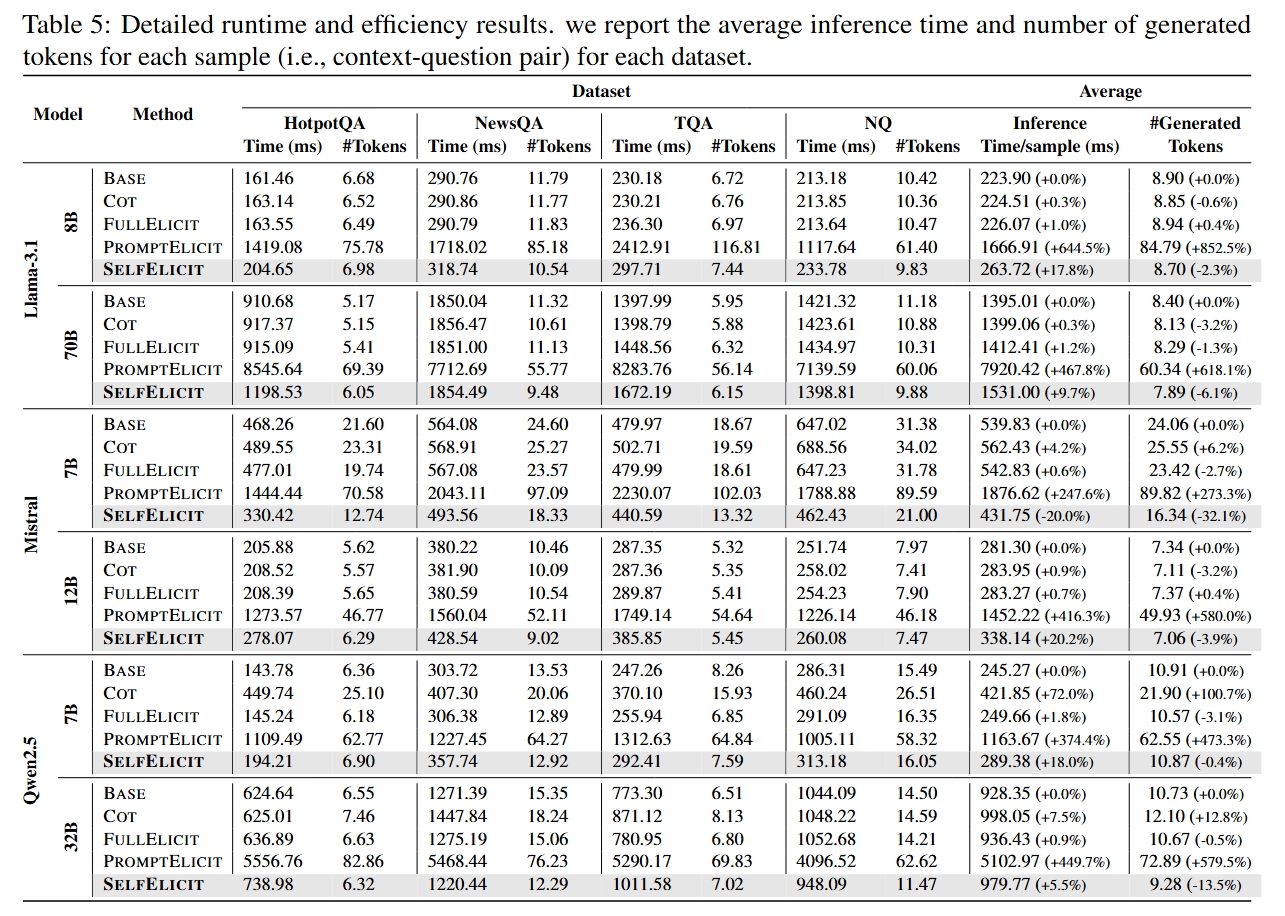 SelfElicit is computationally efficient and does not require additional training.
SelfElicit is computationally efficient and does not require additional training.
## 🗂️ Code Structure
- `self_elicit.py`: Implements the core **SelfElicit** algorithm and other baselines for evidence selection and context highlighting.
- `run_experiment.ipynb`: Provides a Jupyter notebook for running experiments and visualizing results.
- `run_experiment.py`: Command-line interface for running experiments with different models and datasets.
- `config.yaml`: Configuration file specifying model paths, datasets, and experiment settings.
- `args.py`: Parses command-line arguments for running the scripts.
- `dataloader.py`: Handles data loading for QA datasets (e.g., HotpotQA, TriviaQA).
- `eval.py`: Evaluation metrics for QA tasks and evidence selection accuracy.
- `qa_agent.py`: Defines the QA model interface, supporting different LM families.
- `utils.py`: Utility functions for data processing, logging, etc.
### Main modules
1. **args**:
- **get_args**: Function to retrieve and set up arguments for the notebook.
2. **dataloader**:
- **load_data**: Function to load datasets for the experiments.
3. **utils**:
- **get_model_tokenizer_device**: Function to load the model, tokenizer, and device (e.g., GPU or CPU) for running the experiments.
4. **qa_agent**:
- **get_agents_dict**: Function to prepare QA agent instances with different instructions.
- **ContextQuestionAnsweringAgent**: Class for handling context-based question answering tasks.
5. **eval**:
- **evaluate**: Function to evaluate the model's answers against the true answers using metrics like F1 score and Exact Match (EM).
6. **self_elicit**:
- **get_answer_base**: Function to get the base answer from the model.
- **get_answer_cot**: Function to get the answer using Chain-of-Thought (COT) reasoning.
- **get_answer_fullelicit**: Function to get the answer using full elicitation.
- **get_answer_promptelicit**: Function to get the answer using prompt elicitation.
- **get_answer_selfelicit**: Function to get the answer using self-elicit method.